


The best open source AI video generators compared — top models by quality, license and hardware, with Apache 2.0 vs restricted terms and how to choose for commercial use.
| Apache 2.0 Most Permissive License | 8GB Lowest VRAM (LTX-Video) | 14B Wan 2.2 Parameters | $0 Per-Generation Cost | 5+ Production-Ready Models |
| Quick answer: The best open source AI video generators are models with public weights you can download and run yourself. Wan 2.2 leads overall (Apache 2.0, MoE, strong motion), Mochi 1 offers unmatched motion realism with a clean Apache 2.0 license, LTX-Video is fastest on the lowest hardware (Apache 2.0, 8GB VRAM), HunyuanVideo gives top cinematic realism (but a restrictive Tencent license), and CogVideoX is the most reproducible for pipelines. For commercial work, prefer Apache 2.0 models. |
Key Takeaways
- Open source AI video generators have public, downloadable weights you run yourself — no per-generation fee, full control, and the ability to fine-tune on your own data.
- Top models: Wan 2.2 (best overall, Apache 2.0), Mochi 1 (motion realism, Apache 2.0), LTX-Video (fastest, 8GB VRAM, Apache 2.0), HunyuanVideo (cinematic, restrictive license), CogVideoX (reproducible pipelines).
- License is decisive for commercial use: Wan, Mochi 1, LTX-Video and CogVideoX use permissive Apache 2.0, while HunyuanVideo’s Tencent Community License restricts certain deployments and SVD has restrictions.
- Hardware ranges from 8GB (LTX-Video) to 24GB (Wan 14B, Mochi 1, quantized HunyuanVideo) to 60–80GB (HunyuanVideo full); ComfyUI is the standard frontend.
Table of Contents
1. What “Open Source” Means for AI Video
“Open source AI video” gets used loosely, so it’s worth being precise. In practice it means models with public weights you can download and run on your own hardware — whether or not the training pipeline itself is public. Wan, HunyuanVideo, LTX-Video, Mochi 1 and CogVideoX all have downloadable weights you can self-host, and once you’re set up, you don’t pay per generation.
What open models don’t give you is a polished interface, managed infrastructure or a support queue — you own the setup, the updates and the debugging. The shift that happened across 2025–2026 is that these models got good enough for real production work, not just experimentation, with the best of them now competitive with mid-tier commercial tools. This guide ranks them by quality, license and hardware; for the hardware and setup side specifically, pair it with our guide to the best local AI video generator and the broader best AI video generator pillar.

Figure 2: What “open source” means for AI video models
2. Why Choose Open Source?
The open-source advantages are concrete: no per-generation fee, the ability to fine-tune on proprietary data, and full control over the pipeline. Crucially for businesses, open models running locally never send your prompts, reference images or output to external servers — a genuine security advantage for pre-release product footage, unreleased brand assets or confidential client work. Commercial cloud tools, by contrast, win on simpler UX, better support and longer clips.
The trade-off is upfront effort and the realistic break-even point. Getting CUDA installed, a Python environment configured, ComfyUI running and weights downloaded is not click-and-go — the first time can take four to eight hours if you’re not already comfortable with Python environments. In return you get unlimited generation volume and complete control. The honest math: at only three to five clips a week, cloud is probably cheaper once you amortize hardware; at higher volume, open source pulls clearly ahead. It’s the same durability and ownership case made by the broader open ecosystem, and it connects to model choice in our best AI models guide.
There’s also a strategic reason businesses increasingly care about open weights: independence. Relying on a single closed vendor means your pipeline is hostage to its pricing, its terms of service and its continued existence — and 2026 has already shown that even flagship commercial video tools can be discontinued overnight. An open model you’ve downloaded keeps working regardless of what any company decides, which makes it a sound foundation for anything you intend to depend on long-term rather than a quick experiment.
3. The Best Open Source AI Video Generators
The leading open models, with their license and hardware, are summarized below.
| Model | License | Best for · VRAM |
|---|---|---|
| Wan 2.2 (Alibaba) | Apache 2.0 | Best overall, motion · 24GB |
| Mochi 1 (Genmo) | Apache 2.0 | Motion realism · 16–24GB |
| LTX-Video (Lightricks) | Apache 2.0 | Speed · 8–12GB |
| HunyuanVideo (Tencent) | Tencent Community | Cinematic realism · 24–80GB |
| CogVideoX (2B/5B) | Apache 2.0 (2B) | Reproducible pipelines · 16–24GB |
Wan 2.2 from Alibaba is the best overall open source video generator in 2026 — a 14B Mixture-of-Experts model that outperforms several closed commercial systems on VBench benchmarks, with strong motion and readable text in English and Chinese under a permissive Apache 2.0 license. Its honest limitation is resolution: it excels at motion but upscaling is typically needed for full production output. Mochi 1 from Genmo is unmatched for natural motion realism, built on an Asymmetric Diffusion Transformer with strong T5-XXL text encoding, and its Apache 2.0 license makes it the easiest to integrate into a commercial pipeline. LTX-Video from Lightricks is the speed king — a lightweight 700M-parameter model that generates a 5-second clip in under 10 seconds on a capable GPU, runs on as little as 8GB VRAM, and ships under Apache 2.0, with LTX-2.3 adding synchronized audio.
HunyuanVideo from Tencent delivers the most cinematic realism, with a full-attention transformer processing video and text jointly at up to 1280×720 — but it demands heavy hardware (60–80GB for full precision, ~24GB quantized) and ships under the more restrictive Tencent Community License. CogVideoX is the most reproducible and prompt-adherent option, ideal for research and structured pipelines, with its 2B variant under Apache 2.0. Beyond these, SkyReels V1 targets human-centric video, AnimateDiff extends existing Stable Diffusion LoRAs on 8GB cards, and Open-Sora 2.0 pushes research-grade open progress at high hardware cost. For source images to feed these models, see our guide to the best AI tools for generating images.
A useful way to think about the lineup is as a spectrum from speed to quality. At the fast, light end sits LTX-Video, which trades some polish for near-real-time iteration on cheap hardware. In the balanced middle are Mochi 1 and CogVideoX, which run on a single 24GB card and deliver strong, dependable results. At the quality end sit Wan 2.2 and HunyuanVideo, which produce the most impressive output but ask the most of your hardware and, in HunyuanVideo’s case, your legal review. Most creators end up using two: a fast model for drafting and shot-testing, and a heavier model for the handful of hero clips that justify the longer render and higher VRAM.

Figure 3: Top open models grouped by license
4. Licensing: Apache 2.0 vs Restricted
For anything commercial, the license matters as much as the output. The most permissive is Apache 2.0, which permits full commercial use and covers Wan 2.1/2.2, Mochi 1, LTX-Video and CogVideoX (2B) — making them the safe defaults for production, monetized or client work. If Apache 2.0 is a hard requirement for your legal context, Wan and Mochi 1 are the strongest options, with Wan offering the broader feature set (image conditioning, higher resolution, larger scale).
The notable exception is HunyuanVideo, released under Tencent’s Community License, which carries conditions and restricts certain commercial deployments — a dual-license dynamic you must read carefully before shipping. Stable Video Diffusion also has usage restrictions. The practical rule: always check the model card on Hugging Face for current terms before commercial use, because licenses can change between releases. When in doubt, default to a clean Apache 2.0 model; the small quality trade-off versus HunyuanVideo is usually worth the legal certainty. This diligence mirrors the broader caution we cover across generative AI tools.
| 💡 Pro Tip If your output is commercial and you can’t afford legal ambiguity, start with Mochi 1 or LTX-Video. Both are Apache 2.0 with no commercial restrictions, so you avoid the dual-license conditions attached to HunyuanVideo entirely. Reserve HunyuanVideo for internal, research or clearly non-commercial work where its superior cinematic realism is worth navigating the licensing terms. |
5. How to Choose by Goal & Hardware
Pick by your priority. For cinematic visual quality with strong hardware, Wan 2.2 leads. For motion realism, Mochi 1 is unmatched. For speed and rapid iteration on modest hardware, LTX-Video is the clear choice. For the highest realism ceiling when VRAM and licensing aren’t constraints, HunyuanVideo. And for reproducible, prompt-adherent research pipelines, CogVideoX.
Hardware sets the floor. The realistic minimum is 8GB VRAM for LTX-Video; the higher-quality models (Wan 14B, Mochi 1, quantized HunyuanVideo) want 16–24GB — an RTX 4090 or L40 is the sweet spot — while HunyuanVideo at full precision needs 60–80GB (A100 or H100). Browser-based options exist for those without a GPU, but for real control you’ll want a capable card. Match the model to both your goal and your hardware, and check the current README on each model’s GitHub for up-to-date requirements, since quantization keeps lowering the bar. For short-form output specifically, these pair with our guides to the best AI video generator for TikTok and the best free AI image to video generator.
6. Limitations & Getting Started
Open source video has real constraints. Native resolution is often limited (Wan excels at motion but typically needs upscaling), clips are short, base models produce silent output (only LTX-2.3 generates synchronized audio natively), and HunyuanVideo’s base release lacks image conditioning and audio. You also accept the setup cost and the absence of vendor support. These are manageable trade-offs, not dealbreakers, for anyone with volume or privacy needs.
To start, ComfyUI is the de facto frontend, and the ComfyUI Discord, Reddit and GitHub host the most active open-source video communities — workflow sharing and troubleshooting there save hours of solo debugging. Begin with LTX-Video to validate your pipeline quickly on modest hardware, then add Wan 2.2 or Mochi 1 once the basics work. Keep ComfyUI and your nodes updated, since the field moves fast and quantization improvements regularly lower hardware requirements. Used this way, open source gives you a durable, private, unlimited video pipeline — the payoffs are real, they just require accepting the setup cost upfront.
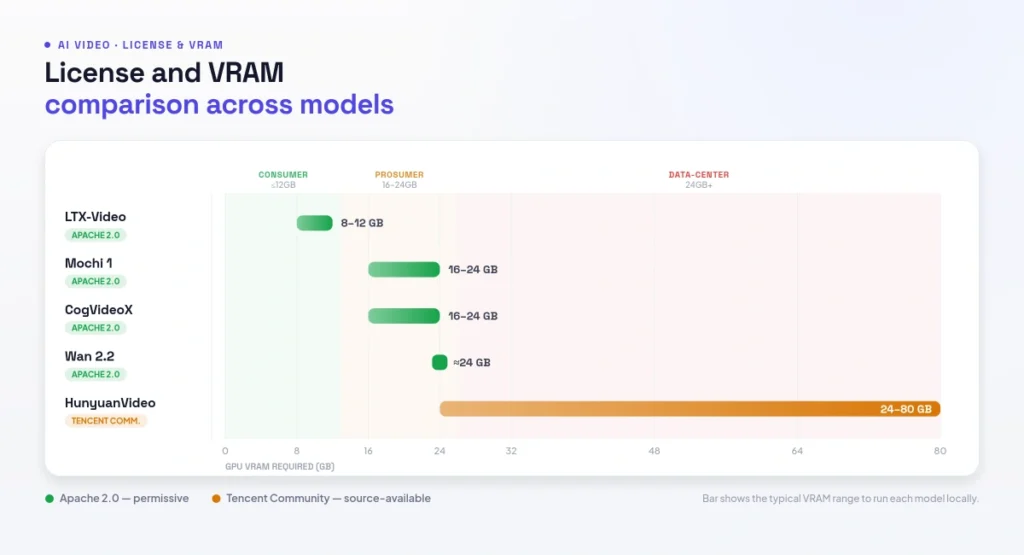
Figure 4: License and VRAM comparison across models
| ⚠️ Important Never assume an open-weight model is free for commercial use — the license, not the price, decides that. HunyuanVideo’s Tencent Community License and Stable Video Diffusion both restrict certain commercial deployments, while Wan, Mochi 1, LTX-Video and CogVideoX use permissive Apache 2.0. Always read the current model card on Hugging Face before using output in a paid product, ad or client deliverable. |
7. Frequently Asked Questions
What is the best open source AI video generator?
Wan 2.2 is the best overall open source AI video generator in 2026 — a 14B Mixture-of-Experts model that outperforms several closed systems on benchmarks, with strong motion and a permissive Apache 2.0 license. For motion realism choose Mochi 1, for speed on low hardware choose LTX-Video, and for maximum cinematic realism choose HunyuanVideo (with a restrictive license).
Are open source AI video models free for commercial use?
It depends on the license, not the price. Wan 2.1/2.2, Mochi 1, LTX-Video and CogVideoX (2B) use Apache 2.0, which permits full commercial use. HunyuanVideo’s Tencent Community License restricts certain commercial deployments, and Stable Video Diffusion has usage restrictions. Always check the current model card on Hugging Face before commercial use.
What hardware do I need to run open source AI video?
The realistic minimum is 8GB VRAM for LTX-Video. Higher-quality models like Wan 14B, Mochi 1 and quantized HunyuanVideo want 16–24GB (an RTX 4090 or L40), while HunyuanVideo at full precision needs 60–80GB (A100 or H100). Quantization keeps lowering these requirements, so check each model’s GitHub README for current numbers.
Which open source model has the best motion?
Mochi 1 is widely regarded as unmatched for natural motion realism, thanks to its Asymmetric Diffusion Transformer architecture and strong text encoding. Wan 2.2 also excels at motion, though it typically needs upscaling for full-resolution production. Both ship under permissive Apache 2.0 licenses, making them strong choices for commercial pipelines.
Is open source cheaper than commercial AI video?
At volume, yes — open models have no per-generation fee once set up. But at only three to five clips a week, cloud is probably cheaper after you amortize hardware cost and the four-to-eight-hour first-time setup. The break-even point depends on your volume, so estimate honestly: heavy or privacy-sensitive workloads favor open source.
Do open source video models generate audio?
Most base models produce silent video only. The exception is LTX-Video’s 2.3 release, which adds synchronized audio generated alongside the video, avoiding the sync drift that occurs when audio is added separately. For other models, you’ll need to add audio in post or pair the visual model with a separate text-to-speech or dubbing tool.
How do I run open source AI video models?
ComfyUI is the de facto frontend for open-source video generation, and most models ship official ComfyUI workflows. You download the weights from Hugging Face, set up a CUDA-enabled Python environment, and load the workflow. The first setup takes several hours, but the active ComfyUI Discord, Reddit and GitHub communities make troubleshooting much faster.
Open source or commercial AI video — which should I use?
Choose open source for unlimited volume, full control, data privacy and fine-tuning on your own data, accepting the setup cost. Choose commercial cloud tools for simpler UX, better support and longer clips with no hardware investment. Many teams use both: open source for high-volume or IP-sensitive work, cloud for quick one-off cinematic shots.
8. Conclusion & Key Takeaways
Open source AI video has reached genuine production quality, and the right model depends on your goal, hardware and — critically — license. Wan 2.2 leads overall under Apache 2.0, Mochi 1 offers unmatched motion with clean licensing, LTX-Video is fastest on the lowest hardware, HunyuanVideo gives top cinematic realism under a more restrictive license, and CogVideoX is the most reproducible for pipelines. For commercial work, default to Apache 2.0 models, verify the model card before shipping, and lean on ComfyUI and its communities to get started. The payoffs — no per-generation fee, full control and data privacy — are real once you accept the setup cost. To go deeper, see our pillar on the best AI video generator tools and the guide to the best local AI video generator.
- Open source = public, downloadable weights; no per-generation fee, full control, fine-tuning on your data.
- Top models: Wan 2.2 (best overall), Mochi 1 (motion), LTX-Video (speed/low VRAM), HunyuanVideo (cinematic), CogVideoX (pipelines).
- License is decisive: Apache 2.0 (Wan, Mochi 1, LTX-Video, CogVideoX) vs restrictive Tencent license (HunyuanVideo).
- Hardware ranges 8GB (LTX-Video) to 24GB (most) to 60–80GB (HunyuanVideo full); ComfyUI is the standard frontend.
- At low volume cloud is cheaper; at scale open source wins — and always self-host for IP-sensitive work.
Open source AI video puts a production-grade pipeline entirely in your hands — no per-clip fees, no data leaving your machine, and the freedom to fine-tune. Pick an Apache 2.0 model that fits your hardware, read the license, and start building on a foundation no vendor can take away.
4 Comments
Pingback: 10 Best AI Tools for Generating Images in 2026-27
Pingback: Best AI Video Generator to Create Stunning Videos Fast
Pingback: Best Free AI Image to Video Generator Worth Trying
Pingback: Best Local AI Video Generator You Can Run Offline