


A developer’s guide to the best AI APIs — the top LLM, image and multimodal providers, how API pricing actually works, multi-model routing, and how to choose the right API for cost, quality and scale.
Key Takeaways
- Best frontier APIs: OpenAI & Anthropic; best value and free tier: Google Gemini; cheapest high-quality: DeepSeek & Mistral.
- Multi-model routers (OpenRouter, AWS Bedrock, LiteLLM) give access to many models through one key — now the production standard.
- Pricing is per token ($0.08–$30 per million); prompt caching (~90% off) and batch processing (50% off) dramatically cut cost.
- Don’t hardcode one provider — route cheap models for easy tasks and frontier models for hard ones to cut spend 60–80%.
Table of Contents
1. What Is an AI API?
An AI API is a way for your software to use a powerful AI model without hosting it yourself. Instead of running a giant model on your own servers, you send a request over the internet — a prompt, an image, a piece of audio — to a provider’s endpoint, and the model sends back a response: generated text, an image, a transcription, or structured data. The “API” (application programming interface) is simply the contract that defines how your code talks to the model. It is what turns a chatbot you visit in a browser into a capability you can build directly into your own product.
The mechanics are straightforward. You sign up for an API key (your credentials), send an HTTP request containing your input and which model you want, and receive a response, paying only for what you use — almost always priced per token (a token is roughly ¾ of a word). There is no infrastructure to manage, no GPUs to buy, and you can switch models with a one-line change. This pay-as-you-go, no-commitment model is now standard across every major provider, which is why building with AI has never been more accessible.
AI APIs are the foundation of almost every AI product you use. The models behind them are the same frontier and open models covered in our best AI models guide — the API is just how developers access them programmatically. If a model is the engine, the API is the ignition and pedals: the interface that lets you actually drive. The rest of this guide covers which APIs are best, what they cost, and how to choose.
The reason APIs matter so much is that they collapsed the barrier to building with AI. A decade ago, using a powerful model meant having the data, the GPUs and the machine-learning expertise to train and run one — out of reach for almost everyone. Today a solo developer can integrate a state-of-the-art model in an afternoon for pennies per request, with the provider handling the hardware, scaling and updates. That democratization is why thousands of AI products have launched in a short span, and why “AI feature” has become an expectation rather than a differentiator. Understanding APIs is therefore not just a developer concern; it is how any organization turns the capability of generative AI into something embedded in its own products and workflows.
2. Types of AI APIs
“AI API” covers several categories, and knowing them helps you find the right tool. The largest and most important is the LLM (text) API — for chat, writing, reasoning, summarization and code, offered by OpenAI, Anthropic, Google and others. Then there are image-generation APIs (for creating visuals from prompts), audio APIs (speech-to-text transcription and text-to-speech voices), video-generation APIs, and embeddings APIs that turn text into vectors for search and retrieval. Increasingly, multimodal APIs handle several of these in one endpoint.
A second, crucial distinction is between first-party provider APIs and aggregator APIs. A first-party API connects you directly to one provider’s models (OpenAI’s API, Anthropic’s API). An aggregator or router — like OpenRouter, AWS Bedrock or AI/ML API — gives you access to models from many providers through a single key and a single bill. Aggregators have become essential because they let you compare models, switch instantly, and route each task to the best or cheapest option without integrating each provider separately. For most production teams, an aggregator is now the smart default rather than a single-provider integration.
It is also worth understanding the common capabilities that sit alongside basic text generation, because they are what turn a model into a useful application. Function calling (or tool use) lets the model trigger your code — querying a database, calling another API — which is the foundation of AI agents. Structured output forces responses into a JSON schema you define, essential for reliable data pipelines. Streaming returns tokens as they are generated for a responsive feel. And vision and audio inputs let multimodal models read images or listen to speech. When comparing APIs, these features often matter more than a small price difference, because they determine what you can actually build and how reliably it will run in production.
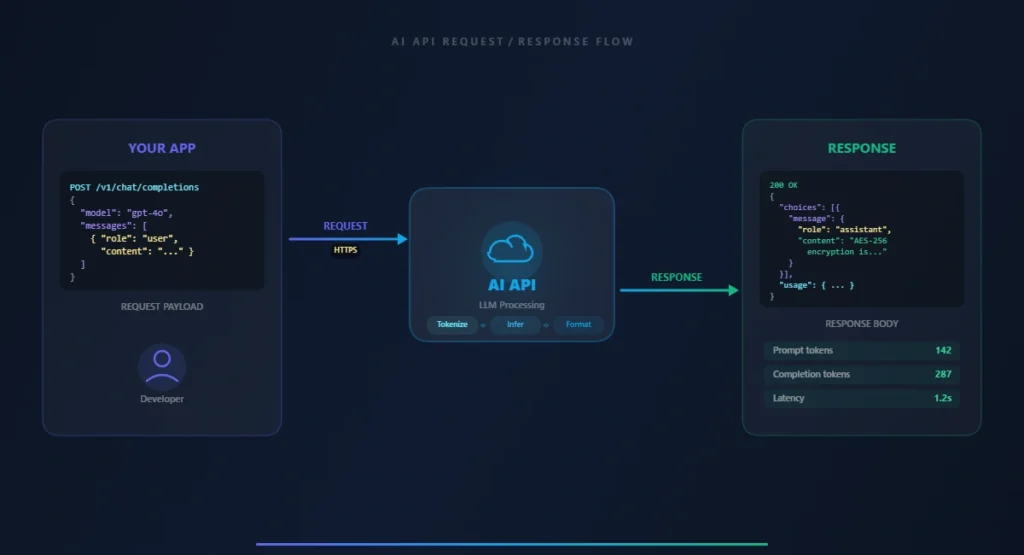
Figure 3: How an AI API request and response works
3. The Best AI APIs Right Now
The market has consolidated around a handful of serious providers plus a strong layer of aggregators and fast-inference specialists. Here are the leaders.
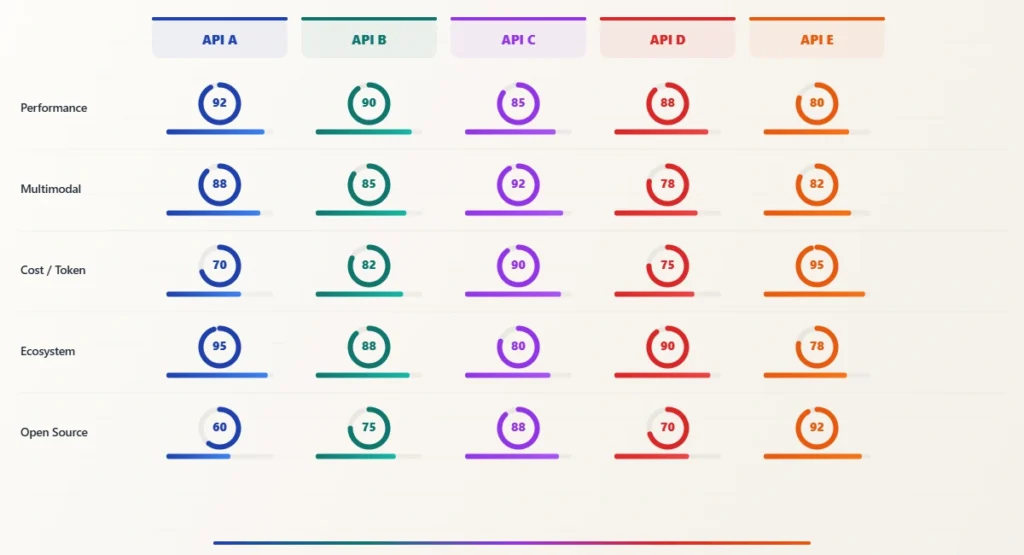
Figure 2: The leading AI APIs compared
3.1 OpenAI — Largest Lineup & Ecosystem
The OpenAI API offers the broadest first-party lineup — the GPT-5 family, budget Nano tiers, dedicated reasoning models, plus DALL·E (image), Whisper (speech) and embeddings — with the most mature tooling, parallel function calling and JSON-schema enforcement. It is the default many teams reach for, with excellent documentation and ecosystem support. The honest limitation: frontier tiers are expensive, and its sheer breadth can be overwhelming for a first project.
3.2 Anthropic — Best for Complex Reasoning & Agents
The Anthropic API serves the Claude family, which leads on complex reasoning, coding and agentic tasks, with native support for the Model Context Protocol (MCP) and precise prompt-cache control. It offers flat-rate pricing at large context windows (no surcharge at 1M tokens), which makes document and RAG pipelines predictable. The honest limitation: no ultra-budget “nano” tier equivalent, so very high-volume simple tasks can be cheaper elsewhere.
3.3 Google Gemini — Best Free Tier & Value
The Google Gemini API offers the widest free tier for testing, strong multimodal capabilities, and excellent price-to-performance — Gemini 3.1 Pro for reasoning and cheap Flash tiers for high volume. It also adds grounding with Google Search. For teams that want to prototype free and scale affordably, it is often the best starting point. The honest limitation: the model and product naming can be confusing, and access spans several Google surfaces.
3.4 DeepSeek & Mistral — Cheapest High-Quality
For cost-sensitive workloads, DeepSeek and Mistral lead. DeepSeek’s models deliver quality rivaling far pricier options at roughly $0.14/$0.28 per million tokens, and Mistral offers competitive open-weight models with commercial APIs at budget rates. Both are ideal when you need near-frontier quality at a fraction of the cost. The honest limitation: ecosystems and tooling are less mature than the big three, and peak capability still trails the frontier.
3.5 OpenRouter & AWS Bedrock — Best Multi-Model Access
Aggregators are the production standard. OpenRouter gives you hundreds of models from every major provider through one key and one bill, with built-in routing and failover. AWS Bedrock offers multi-provider access with enterprise security and AWS integration. AI/ML API similarly bundles 400+ text, image, video and speech models behind a single key. The honest limitation: a thin dependency layer between you and the provider, and pricing can carry a small markup.
3.6 Groq, Together & Fireworks — Fastest Inference
When latency is critical, specialized inference providers win. Groq delivers exceptionally fast token generation, while Together AI and Fireworks AI lead on throughput and latency for open models. These are the choice for real-time applications where every millisecond counts, and for running open-weight models at scale affordably. The honest limitation: they focus on inference for select models rather than offering proprietary frontier models of their own.
4. How AI API Pricing Works
AI API pricing is almost always per token, with separate rates for input (your prompt) and output (the model’s response), quoted per million tokens. Output is typically several times more expensive than input because it requires more compute. Rates span an enormous range: the cheapest high-quality models start around $0.10–$0.14 per million input tokens (GPT Nano tiers, Mistral Small, DeepSeek), while frontier flagships can reach $15–$30+ per million output tokens. Image generation runs roughly $0.005–$0.05 per image.
| Tier | Example Models | Price (per M tokens, in/out) |
|---|---|---|
| Budget | GPT Nano, Mistral Small, DeepSeek V3 | ~$0.10–$0.28 |
| Mid / value | Gemini Flash, Claude Sonnet | ~$0.40–$3 / $1–$15 |
| Frontier | GPT-5.x, Claude Opus, Gemini Pro | ~$2–$15 / $12–$75 |
| Image | Various image APIs | ~$0.005–$0.05 / image |
The crucial insight is that the cheapest model per token is not the cheapest model per task — retry rates, output quality and context overhead determine true cost. Two powerful levers cut bills dramatically: prompt caching (up to ~90% off repeated input, ideal for RAG and system prompts) and batch processing (around 50% off for non-real-time jobs). Combined, they can drop effective cost to roughly a quarter of standard rates. A chatbot doing 100M output tokens a month might pay around $1,000 on a frontier model or under $50 on a cheap one of similar quality for conversational tasks — which is why model choice at scale creates order-of-magnitude differences.
| 💡 Pro Tip Estimate cost during a pilot with this formula: monthly cost ≈ (daily requests × avg input tokens × input price/1M + daily requests × avg output tokens × output price/1M) × 30. Buffer 2–3x for prompt iteration, then plan for a 20–30% reduction in your first quarter as you add caching, routing and context compression. |
5. Best AI API by Use Case
The right API depends entirely on the job. The table below maps common needs to the best fit.
| Use Case | Best Pick | Why |
|---|---|---|
| Complex reasoning / agents | Anthropic (Claude) | Leads reasoning, coding, agentic tasks |
| Broadest features / ecosystem | OpenAI | Largest lineup and tooling |
| Free prototyping / value | Google Gemini | Widest free tier, strong price-performance |
| High-volume / lowest cost | DeepSeek / Mistral / Gemini Flash | Near-frontier quality, fraction of cost |
| Many models, one key | OpenRouter / AWS Bedrock | Multi-provider access and routing |
| Real-time / low latency | Groq / Fireworks | Fastest token generation |
| Enterprise security / RAG | AWS Bedrock / Cohere | Compliance, multi-model, RAG focus |
A useful rule of thumb: about 80% of applications work fine with a mid-value model in the roughly $0.40–$2.50 per million output-token range. Reserve frontier APIs for the genuinely hard tasks — complex reasoning, difficult code, customer-facing quality — and route everything else to cheaper models. This single habit is the biggest cost lever most teams have, and it is why the next section matters so much.
Use case also shapes which provider features you should weight. A retrieval-augmented (RAG) document pipeline benefits most from prompt caching and flat-rate long-context pricing, where Anthropic and Google are strong. A high-volume classification or extraction job favors the cheapest capable model plus batch processing. A real-time customer-facing chatbot prioritizes low latency, pointing toward fast-inference providers or a nimble mid-tier model. An agentic workflow that calls tools needs robust function calling and reliability, where OpenAI and Anthropic lead. Matching the workload’s true requirements — not just its headline category — to the provider’s strengths is what separates a cost-efficient deployment from one that quietly overpays or underperforms.
6. Multi-Provider Routing & Cost Optimization
The production standard in modern AI engineering is multi-provider routing: rather than hardcoding one provider, you send most requests to cheap models and escalate only the complex ones to frontier models. Tools like LiteLLM, Portkey and OpenRouter handle the routing, failover and cost tracking automatically. This approach eliminates single-provider downtime risk and, according to industry reports, can cut costs 60–80% versus defaulting everything to a premium model.
The economics are stark. The same conversational task can cost ten times more on a frontier model than on a capable budget model that handles it just as well. Yet only about a fifth of organizations track AI spend at the transaction level — meaning most are overpaying without knowing it. The fix is a deliberate routing and measurement strategy: classify tasks by difficulty, assign each to the cheapest model that meets the quality bar, layer in caching and batch where applicable, and monitor cost per transaction against business value. Teams that do this turn AI from an unpredictable expense into a controllable one.
This is also the strongest argument for building provider-agnostic from day one. Because new models ship constantly and prices keep falling, an application wired to a single provider faces repeated migration work and misses cheaper or better options. Routing through an aggregator keeps you flexible, captures every new release as an upgrade, and protects you from any one provider’s outages or price changes — the same model-agnostic principle that runs through our best AI models guide.
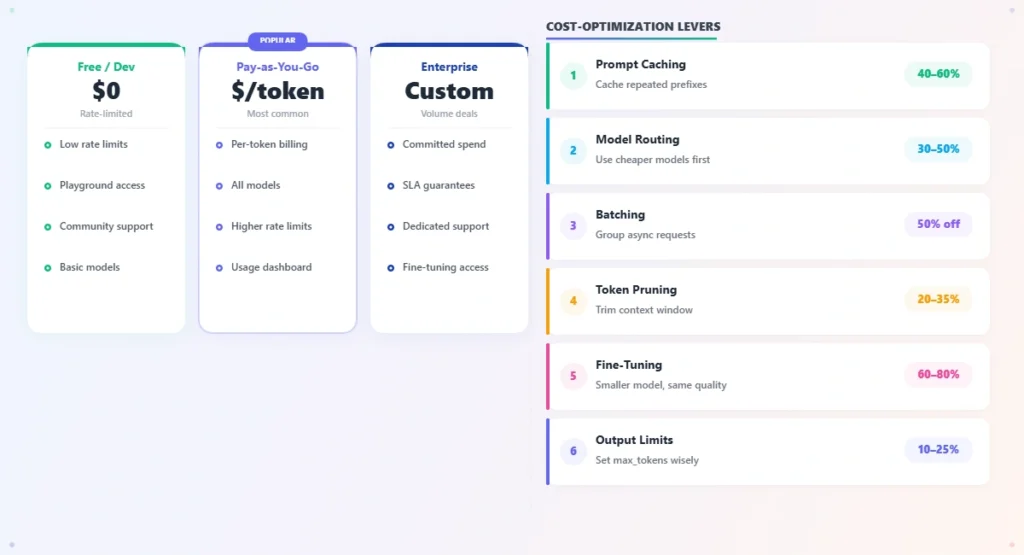
Figure 4: AI API pricing tiers and cost-optimization levers
7. How to Choose an AI API
Start with four questions. First, what is your primary task? Reasoning and agents lean Anthropic; broad features lean OpenAI; value and prototyping lean Gemini; cost-sensitive volume leans DeepSeek, Mistral or a Flash tier. Second, what is your budget at scale? Estimate cost per task, not per token, and model your real input/output volumes — the difference between providers can be an order of magnitude at production scale, so a few hours of cost modeling up front can save thousands of dollars a month later.
Third, what are your non-negotiables? Latency (choose a fast-inference provider), data sovereignty (consider self-hosting or an enterprise tier), compliance (AWS Bedrock, Azure or enterprise agreements), and context length (some providers offer flat-rate pricing at 1M tokens). Fourth, how much flexibility do you need? If you expect to compare or switch models, start with an aggregator rather than a single-provider key. Then validate by building a small pilot — a real task on a shortlist of two or three options — and measure SDK quality, latency, error handling and cost before committing.
One more decision: API versus self-hosting. APIs win for almost everyone — no infrastructure, instant access, pay-as-you-go. Self-hosting an open model only becomes cheaper at high, steady utilization (roughly when monthly API spend exceeds $5,000–$10,000) or when you need data sovereignty or guaranteed latency. Below that threshold, the API providers win on cost and simplicity, so most teams should start with an API and revisit self-hosting only at scale.
| ⚠️ Important API costs can spiral without monitoring — a runaway loop, an un-cached system prompt, or routing everything to a frontier model can multiply your bill overnight. Set hard spend limits, track cost per transaction, and add caching and routing early. The most expensive hidden cost in AI is the spend you are not measuring. |
8. Beyond Raw APIs: Coding & Low-Code Tools
Not everyone needs to call a raw API. A whole layer of tooling sits on top to make AI accessible without heavy engineering. AI coding tools — assistants that write, explain and debug code, including against APIs — have become essential for developers; our guide to the best AI coding tools covers the leaders. Low-code and no-code AI platforms let teams build AI-powered apps and workflows visually, wiring models into business processes without writing integration code — see our roundup of low-code AI platforms.
Documentation and maintainability matter too. As AI gets woven into more systems, keeping APIs and codebases well-documented becomes critical, and a new generation of AI code documentation tools automates the tedious work of writing and updating docs. Together, these layers mean that whether you are a developer calling endpoints directly, a team building on a low-code platform, or a business automating a workflow, there is an on-ramp to AI that fits your skills — and the API underneath is what powers them all. For the wider toolkit, see our guide to the best AI tools for business.
The practical implication is that “using AI APIs” is no longer a single skill but a spectrum. At one end, engineers wire models into products with raw API calls, function calling and custom routing. In the middle, developers lean on AI coding assistants to write that integration faster than ever. At the other end, non-technical teams assemble AI workflows on low-code platforms that call the same APIs behind a visual interface. All three are growing quickly, and many organizations use all three at once — engineers building the core product, low-code tools handling internal automations, and AI assistants accelerating everyone. Choosing where on that spectrum a given project belongs is itself an important decision, and it usually comes down to how custom the logic is and who will maintain it.
9. Frequently Asked Questions
What is the best AI API?
For frontier quality, OpenAI and Anthropic lead; for the widest free tier and value, Google Gemini; and for the lowest cost at high quality, DeepSeek and Mistral. For access to many models through one key, multi-model routers like OpenRouter and AWS Bedrock are the production standard. The best choice depends on your task, budget and scale.
How much does an AI API cost?
AI APIs charge per token, separately for input and output, quoted per million tokens. Rates range from about $0.10 per million for budget models to $30+ for frontier tiers, with output costing more than input. Prompt caching (up to ~90% off) and batch processing (around 50% off) can cut effective costs to roughly a quarter of standard rates.
What is the cheapest AI API?
Among high-quality options, budget tiers like GPT Nano and Mistral Small start around $0.10 per million input tokens, and DeepSeek V3 offers excellent quality at roughly $0.14/$0.28. Some open models are available free through OpenRouter with rate limits. The cheapest per task, though, depends on quality and retry rates, not just headline price.
Can I access multiple AI providers through one API?
Yes. Aggregators like OpenRouter, AWS Bedrock and AI/ML API give you access to models from OpenAI, Anthropic, Google, Meta, DeepSeek and more through a single key and one bill. This lets you compare models, route each task to the best or cheapest option, and switch providers without separate integrations — now the standard production approach.
What is the difference between an AI API and an AI model?
An AI model is the trained system that generates output; an AI API is the interface that lets your software send requests to that model and receive responses over the internet. The model is the engine; the API is how you access and control it programmatically without hosting it yourself.
Do I need coding skills to use an AI API?
Basic coding helps for calling an API directly, but you do not need to be an expert — most providers offer clear SDKs and documentation. If you prefer not to code, low-code and no-code AI platforms let you build AI-powered apps visually, and AI coding tools can write the integration code for you.
Should I use an AI API or self-host a model?
For most teams, an API is better — no infrastructure, instant access, and pay-as-you-go pricing. Self-hosting an open model becomes cheaper only at high, steady utilization (roughly when monthly API spend exceeds $5,000–$10,000) or when you need data sovereignty or guaranteed latency. Start with an API and revisit self-hosting at scale.
How do I reduce AI API costs?
The biggest levers are routing (send easy tasks to cheap models, hard ones to frontier), prompt caching (up to ~90% off repeated input), and batch processing (around 50% off non-real-time jobs). Also track cost per transaction, set spend limits, and choose the cheapest model that meets your quality bar rather than defaulting to a premium one.
10. Conclusion & Key Takeaways
AI APIs are how AI gets built into real products, and the market gives you remarkable choice: frontier quality from OpenAI and Anthropic, unbeatable value and a free tier from Google Gemini, rock-bottom pricing from DeepSeek and Mistral, and one-key access to all of them through aggregators like OpenRouter and AWS Bedrock. The winning strategy is not to pick one provider and hope, but to build provider-agnostic, route by task, and measure cost per transaction — capturing every new model as an upgrade while keeping spend under control. To go deeper, see our guides to the best AI models behind these APIs, generative AI, and the best AI tools for business.
- Best frontier APIs: OpenAI & Anthropic; best value: Google Gemini; cheapest high-quality: DeepSeek & Mistral.
- Aggregators (OpenRouter, AWS Bedrock) give many models through one key — the production standard.
- Pricing is per token ($0.08–$30 per million); caching (~90% off) and batch (50% off) slash costs.
- Route cheap models for easy tasks and frontier for hard ones to cut spend 60–80%.
- Use an API unless you hit high, steady scale; build provider-agnostic and track cost per transaction.
An AI API turns a frontier model into a feature you can ship — but the real skill is using them economically: route by task, cache aggressively, stay provider-agnostic, and measure what you spend. Build flexibly, and every new model becomes an upgrade.
4 Comments
Pingback: Best AI Code Documentation Tools That Write Docs for You
Pingback: Best Agentic AI Tools – Top Picks [Tested & Ranked]
Pingback: Best AI Coding Tools: Best for Developers
Pingback: Best AI Phone Call Agent to Automate Every Call