


A clear guide to AI hallucinations — what they are, why language models invent false information, how common they are, the real risks, and the proven ways to reduce them.
| 15–52% Benchmark Hallucination Range | 30–70% Hallucinations Cut by RAG | 77% Businesses Concerned | <2% Best Grounded Rate | 5 Main Causes |
| Quick answer: AI hallucinations are confident, plausible-sounding outputs that are actually false or fabricated. They happen because language models predict the most likely next word, not the most truthful one — so they can invent facts, citations or details. Hallucination rates range widely (roughly 15–52% on benchmarks), but you can cut them sharply with retrieval-augmented generation (RAG), careful prompting, source citations and human verification. |
Key Takeaways
- AI hallucinations are confident but false outputs — a built-in consequence of how language models predict text, not a simple bug.
- Causes include next-token prediction, training-data gaps and bias, stale knowledge, ambiguity, and overconfident calibration.
- Rates vary widely (~15–52% on benchmarks, higher in specialized domains); RAG can cut them 30–70%, and strong grounding can reach under 2%.
- You can’t fully eliminate hallucinations, but RAG, good prompting, source citations and human verification reduce them dramatically.
Table of Contents
1. What Are AI Hallucinations?
An AI hallucination is when a generative AI model produces output that sounds confident and plausible but is actually false, fabricated or unsupported. The model might invent a statistic, cite a study that doesn’t exist, attribute a fake quote, or describe a feature a product doesn’t have — all delivered in the same fluent, authoritative tone as its correct answers. The term became so widely used that “hallucinate” was named a dictionary Word of the Year.
The critical thing to understand is that hallucinations are not a glitch the way a software bug is. They are a natural consequence of how large language models work — which is why even the best models still produce them, and why understanding the phenomenon matters for anyone using AI. To grasp the root cause it helps to know what an LLM is and how it generates text.
This guide explains why hallucinations happen, how common they are, the risks they create, and — most usefully — the proven techniques to reduce them. They are a key limitation to weigh when choosing among the best AI models, since hallucination rates differ meaningfully between them.
2. Why Do AI Models Hallucinate?
Hallucinations stem from how language models are built. At their core, LLMs are next-token predictors: they generate text by predicting the most statistically likely next word, not the most truthful one. When the model is uncertain, it doesn’t stop — it produces the most plausible-sounding continuation, which can be a confident fabrication. There is no built-in “fact checker” separating what it knows from what it is inventing.
Five causes compound this. First, next-token prediction optimizes for plausibility, not truth. Second, training-data gaps and bias mean models learn from internet text that includes errors and misinformation. Third, stale knowledge: a model’s training has a cutoff date, so it can confidently give outdated answers. Fourth, ambiguous or complex prompts push the model to fill gaps with guesses — and research shows hallucinations rise with larger inputs and harder queries. Fifth, poor confidence calibration: models often present false information with the same certainty as true facts, which is what makes hallucinations so dangerous.
A useful mental model is that an LLM is less like a database and more like an extremely well-read improviser. It has absorbed vast patterns of how language fits together, and it produces text that matches those patterns convincingly — but it has no separate store of verified facts to check against, and no internal sense of “I don’t actually know this.” So when you ask about something sparse or absent in its training, it doesn’t return an error; it generates the kind of answer that would be plausible if it were true. That is why hallucinations cluster around obscure details, very recent events, precise figures and specific citations — exactly the places where plausible-sounding text is easiest to generate and hardest for the model to verify.
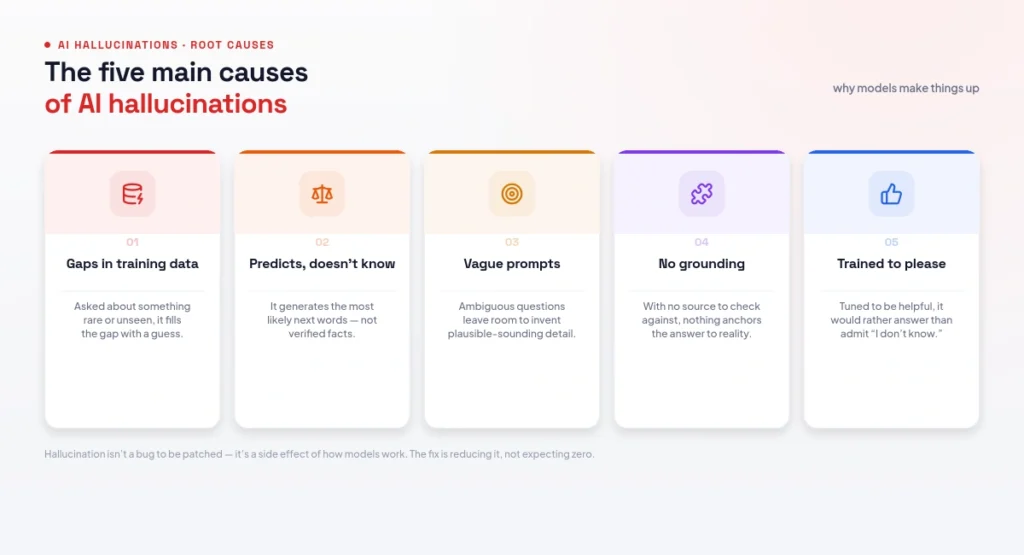
Figure 2: The five main causes of AI hallucinations
3. How Common Are Hallucinations?
Hallucination rates vary enormously by model, domain and task, so there is no single number — and the often-cited “30% problem” is media shorthand, not a formal metric. That said, the research gives useful ranges. Studies have found LLMs hallucinate roughly 15–20% on factual queries without external grounding, and a 2026 benchmark across 37 models reported rates between 15% and 52%. Specialized domains are worse: one analysis of medical case summaries found hallucinations as high as 64% without mitigation.
Two patterns are worth noting. First, grounding dramatically lowers rates — on well-grounded summarization tasks, top models have reached 0.7–1.5%. Second, the newest, most capable models are not automatically safer: some reasoning models show higher rates than earlier versions, suggesting a trade-off between reasoning depth and factual accuracy. Among current models, the best perform in the low single digits while open-source models often sit at 15–30%, so model choice genuinely matters. Unsurprisingly, about 77% of businesses report concern about hallucinations.

Figure 3: Hallucination rates vary widely by model and domain
4. The Real Risks of Hallucinations
Because hallucinations are delivered confidently, they create real-world risk when output isn’t verified. In legal work, fabricated case citations have led to sanctions, and analyses link hallucinations to liability risk in a notable share of AI-assisted legal workflows. In healthcare, a fabricated detail in a summary could affect a decision. In business, enterprises report financial losses tied to hallucinations in a meaningful fraction of deployments, and a fabricated product claim or statistic can damage credibility.
The deeper risk is misplaced trust. Because AI is right so often and sounds equally confident when wrong, users can stop checking — exactly when checking matters most. This is why hallucinations are not just a technical curiosity but a governance issue: any serious deployment, especially in the high-value functions described in our guide to why generative AI is important, needs verification built into the workflow rather than bolted on after a mistake.
There is also a subtler, reputational dimension. A single confidently wrong answer that reaches a customer or appears in published work can erode trust in an entire AI initiative, making stakeholders wary of tools that are genuinely useful elsewhere. That asymmetry — many quiet wins, one loud failure — is why mature teams treat hallucination management as a first-class part of any rollout, not an afterthought. Setting expectations honestly with users, labeling AI-generated content, and keeping a clear human accountability point for anything published all help preserve trust even when the occasional error slips through.
| ⚠️ Important Never use AI output for high-stakes decisions — legal, medical, financial — without independent verification. Hallucinations are delivered with the same confidence as correct answers, so confidence is not a reliable signal of accuracy. Treat every factual claim, citation and statistic from an AI as a draft to be checked, not a verified fact. |
5. How to Reduce AI Hallucinations
You cannot eliminate hallucinations, but you can reduce them dramatically. The single most effective technique is retrieval-augmented generation (RAG), which grounds the model’s answers in trusted, retrieved documents rather than relying on its training memory. RAG reduces hallucination rates by roughly 30–70% across domains and can push grounded tasks under 2%. Crucially, RAG works only if the underlying data is well-governed — on stale or unclassified sources, retrieval can still produce high fabrication rates, so the rule is RAG plus good data, not RAG alone. The trade-offs between this approach and others are covered in our guide to fine-tuning vs RAG.
Several other techniques stack on top. Better prompting — being specific, providing context, and explicitly allowing the model to say “I don’t know” — has been shown to cut hallucinations by around 20 percentage points; see our guide to prompt engineering. Source citations let you verify claims and discourage fabrication. Combining RAG with fine-tuning can reduce rates by up to half, and advanced systems add span-level verification — checking each generated claim against the retrieved evidence and flagging anything unsupported. The table below summarizes the main levers.
| Technique | Effect on Hallucinations |
|---|---|
| Retrieval-augmented generation (RAG) | Cuts rates ~30–70%; grounded tasks under 2% |
| Better prompting + “I don’t know” | ~20 percentage-point reduction |
| Source citations | Enables verification; discourages fabrication |
| RAG + fine-tuning | Up to ~50% reduction |
| Span-level / claim verification | Flags unsupported claims after generation |
The right combination depends on who you are. An everyday user gets most of the benefit from the simplest levers — using a tool that searches and cites the web, prompting carefully, and verifying important claims by hand. A business building an AI product, by contrast, will typically invest in a full RAG pipeline over governed data, add automatic claim verification, and choose a low-hallucination model, because at scale even a small fabrication rate multiplied across thousands of responses becomes a real liability. The encouraging news is that these layers are additive: each one you add chips away at the problem, and stacking them is how the most reliable systems push real-world hallucination rates down to the low single digits.
6. Best Practices for Users
Even without building RAG pipelines, everyday users can sharply cut their exposure to hallucinations. Verify anything that matters — facts, figures, citations, names and dates — against a primary source before relying on it. Ask for sources and check that they actually exist and say what the model claims. Provide context in your prompt rather than relying on the model’s memory, and give the model an out by telling it that admitting uncertainty is acceptable.
A few more habits help. Use a tool that cites and searches the web for factual questions, since live grounding beats relying on training memory. Be extra skeptical with specialized or niche topics, recent events, and very long or complex prompts, where rates are highest. And choose your model with hallucination performance in mind — see our Claude AI guide and the broader comparison in best AI tools for business. The goal is not to distrust AI but to use it the way a smart editor uses a fast but fallible junior researcher: invaluable, but always checked.
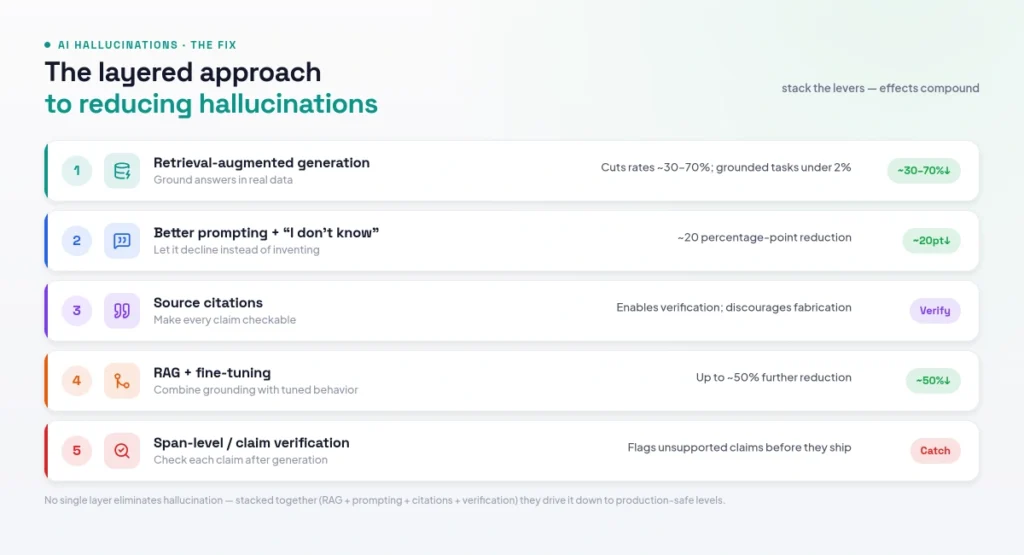
Figure 4: The layered approach to reducing hallucinations
| 💡 Pro Tip Add one short instruction to your prompts: “If you’re not sure, say so rather than guessing, and cite your sources.” This simple framing measurably reduces fabrication by giving the model permission to admit uncertainty instead of inventing a confident answer — one of the easiest, highest-impact habits for everyday AI use. |
7. Frequently Asked Questions
What is an AI hallucination?
An AI hallucination is when a generative AI model produces output that sounds confident and plausible but is actually false, fabricated or unsupported — for example inventing a statistic, citing a non-existent study, or describing a feature that doesn’t exist. It’s delivered in the same fluent tone as correct answers, which is what makes it tricky.
Why do AI models hallucinate?
Because language models are next-token predictors — they generate the most statistically likely next word, not the most truthful one. When uncertain, they produce a plausible-sounding continuation rather than stopping. This is compounded by training-data gaps and bias, stale knowledge, ambiguous prompts, and poor confidence calibration.
How common are AI hallucinations?
Rates vary widely by model and task. Studies find roughly 15–20% on factual queries without grounding, and a 2026 benchmark across 37 models reported 15–52%. Specialized domains like medicine can be much higher. Strong grounding can lower rates to under 2%, and top models perform in the low single digits.
Can AI hallucinations be eliminated?
No, not entirely — they are inherent to how language models work. But they can be reduced dramatically. Retrieval-augmented generation cuts rates 30–70%, good prompting and citations help further, and verification systems catch remaining errors. The realistic goal is to minimize and catch hallucinations, not to eliminate them completely.
Does RAG stop hallucinations?
RAG greatly reduces hallucinations by grounding answers in retrieved documents — often 30–70% fewer, and under 2% on well-grounded tasks — but it does not eliminate them. RAG on stale or ungoverned data can still fabricate, so the best results come from RAG plus good data governance and claim-level verification.
How do I reduce hallucinations in my prompts?
Be specific and provide context rather than relying on the model’s memory, explicitly allow it to say “I don’t know,” ask for sources, and break complex requests into steps. This kind of prompting has been shown to cut hallucinations by around 20 percentage points. Always verify important claims regardless.
Do newer AI models hallucinate less?
Usually, but not always. The best current models hallucinate in the low single digits, far better than open-source models at 15–30%. However, some reasoning-focused models show higher rates than earlier versions, suggesting a trade-off between reasoning depth and factual accuracy, so newer doesn’t automatically mean safer.
Are hallucinations dangerous?
They can be, because they’re delivered confidently and may go unchecked. Fabricated legal citations have led to sanctions, errors in medical summaries could affect decisions, and businesses report financial losses tied to hallucinations. The risk is highest when output isn’t verified, which is why human review is essential for anything consequential.
8. Conclusion & Key Takeaways
AI hallucinations are confident but false outputs — an inherent feature of how language models predict text, not a bug to be patched away. They happen because models optimize for plausibility over truth, compounded by data gaps, stale knowledge and overconfidence. Rates vary widely and can be serious, but they are highly manageable: grounding with RAG, careful prompting, source citations and human verification cut them dramatically. The practical takeaway is to treat AI as a brilliant but fallible assistant whose factual claims always deserve a check. To go deeper, see our pillar on the best AI models and the guide to fine-tuning vs RAG.
- Hallucinations are confident, false outputs caused by next-token prediction, not a simple bug.
- Five main causes: prediction over truth, data gaps/bias, stale knowledge, ambiguity, and poor calibration.
- Rates range ~15–52% on benchmarks; RAG cuts them 30–70%, grounding can reach under 2%.
- Reduce them with RAG + good data, prompting, citations and verification.
- Always verify important AI claims — confidence is not a signal of accuracy.
AI hallucinations are the price of fluency — but they’re manageable. Ground your AI in real sources, prompt it to admit uncertainty, and verify what matters, and you get the speed of AI with the reliability your work demands.
8 Comments
Pingback: AI and Analytics: The Complete Guide to AI Data
Pingback: Best AI Agent – Top Picks Tested & Compared
Pingback: Best AI Models 2026: GPT-5.5 vs Claude vs Gemini vs DeepSeek
Pingback: What is Prompt Engineering? A Complete Beginner Guide
Pingback: Fine-Tuning vs RAG: Which AI Approach Wins in 2026?
Pingback: Generative AI for Content Creation That Saves Hours
Pingback: Best AI Tools for Business to Scale Without Extra Staff
Pingback: How Does Generative AI Work – Simply Explained