


What LLMEO is, how large language models like ChatGPT, Claude and Gemini retrieve and cite content, the strategies that earn brand mentions in AI answers, and how to measure your LLM visibility.
| 4.4x Higher AI-Visitor Conversion | 987M+ People Reached via LLMs | +40% Visibility from Citing Sources | 5+ Sources for Strong Co-Citation | 3 Retrieval Mechanisms to Win |
| Quick answer: LLMEO (large language model optimization) is the practice of optimizing your content, website and brand so large language models like ChatGPT, Claude, Gemini and Perplexity cite and recommend you in their answers. Because LLMs retrieve through RAG, embeddings and training data, LLMEO focuses on technical crawlability, clear structure, cited authority, freshness, and consistent mentions across trusted sources. |
Key Takeaways
- LLMEO optimizes content to be cited and recommended by LLMs (ChatGPT, Claude, Gemini, Perplexity) — measured by mention rate, not rank.
- LLMs retrieve mostly via RAG and live web search, so technical crawlability (allow AI bots, IndexNow, server-rendered HTML) is the foundation.
- Citing sources lifts visibility roughly 40% (Princeton); co-citation across 5+ independent sources is the strongest off-page signal.
- LLMEO is a close sibling of GEO and complements SEO and AEO — build real authority rather than trying to “game” your way into AI answers.
Table of Contents
1. What Is LLMEO?
LLMEO — large language model (engine) optimization — is the practice of structuring and optimizing your content, website and brand presence so large language models discover it, trust it, and cite or recommend it when answering user questions. Where SEO aims to rank a page in a list of links, LLMEO aims to get your brand mentioned, cited and recommended inside conversational AI responses from tools like ChatGPT, Claude, Gemini and Perplexity. It is the same fundamental shift as the rest of AI search, applied specifically to how language models choose their sources.
The opportunity is large and growing. Together, the major LLMs now influence how over 987 million people find information, and AI search visitors reportedly convert about 4.4 times better than traditional organic visitors, because someone who arrives on an AI recommendation arrives pre-qualified and pre-trusted. With LLM-driven traffic projected to rival traditional search in business value within a couple of years, getting mentioned by these models is no longer a nice-to-have — it is a channel to build now.
LLMEO sits inside the broader practice of generative engine optimization; the two terms are often used interchangeably, with LLMEO emphasizing the language-model retrieval mechanics specifically. It is closely related to answer engine optimization (the extraction side) but focuses on the deeper question of how an LLM decides which sources to pull from and quote in the first place.
Why does being cited by an LLM matter so much? Because a recommendation inside a conversational answer carries a level of trust that a blue link never did. When ChatGPT or Gemini names your brand as the answer to a buyer’s question, the user receives it as a vetted suggestion rather than one option among ten — which is precisely why AI-referred visitors arrive further along in their decision and convert at far higher rates. As more discovery shifts into these conversations, the brands an LLM consistently mentions effectively become the shortlist, while those it never names disappear from consideration entirely. LLMEO is how you make sure you are on that shortlist.
2. LLMEO vs GEO vs SEO
These disciplines are parallel layers, not competitors. SEO gets your pages crawled, indexed and ranked. LLMEO gets your content cited when language models generate answers. GEO is the umbrella for getting cited across all generative engines, and AEO handles being extracted as a direct answer. The brands winning today run them simultaneously, because they reinforce each other: strong SEO and crawlability feed the retrieval systems that LLMEO targets.
| Dimension | SEO | LLMEO |
|---|---|---|
| Goal | Rank in the link list | Get cited & recommended by LLMs |
| Success unit | Position 1–10 | Mention rate / share of voice |
| How results work | Deterministic ranking | Non-deterministic — varies per answer |
| Key levers | Keywords, links, technical SEO | Crawlability, structure, citations, co-mentions |
| Where it shows | Results page | ChatGPT, Claude, Gemini, Perplexity |
The most important mindset shift is that LLMs are non-deterministic — they produce different answers each time, so there is no “position one.” Visibility is about frequency: the share of relevant prompts where your brand appears. That is why LLMEO success is tracked as a mention rate or share of voice over time, compared against competitors, rather than a fixed ranking. For the tactic-level playbook, see our guide to LLMEO strategies.
3. How LLMs Retrieve & Cite Content
To optimize for LLMs, you need to understand the three ways they get information. The first is training data — the static knowledge a model learned during training. Influencing this is theoretically possible but only at massive scale and with unpredictable results, so it is not a realistic lever for most organizations. The second, and most actionable, is retrieval-augmented generation (RAG): when a model has live web access, it runs a real-time search, reads the top results, and synthesizes an answer from them. The third is vector embeddings, which determine semantic relevance when a system selects which content to retrieve.
The RAG path is where LLMEO pays off, because it behaves much like optimizing for featured snippets — just with more variables and less predictability. A model retrieves real-time information, weights it for relevance and recency, and generates wording from it. Critically, the live-web browsing in some assistants is powered by existing search indexes, which means your traditional search visibility directly feeds whether you get retrieved. Optimizing for RAG means matching or outperforming the format, clarity and authority of the content already being cited for your target questions.
Embeddings are worth understanding too, because they govern which content gets pulled in the first place. When a system retrieves information, it converts both the query and candidate passages into vectors and selects the ones that are semantically closest — not the ones that merely share keywords. The practical implication is that LLMEO rewards writing about a topic comprehensively and in natural language, covering the concepts and entities around a question rather than repeating an exact phrase. Content that thoroughly and clearly addresses the meaning behind a query is what surfaces in semantic retrieval, which is why depth and clarity consistently beat keyword density in the LLM era.
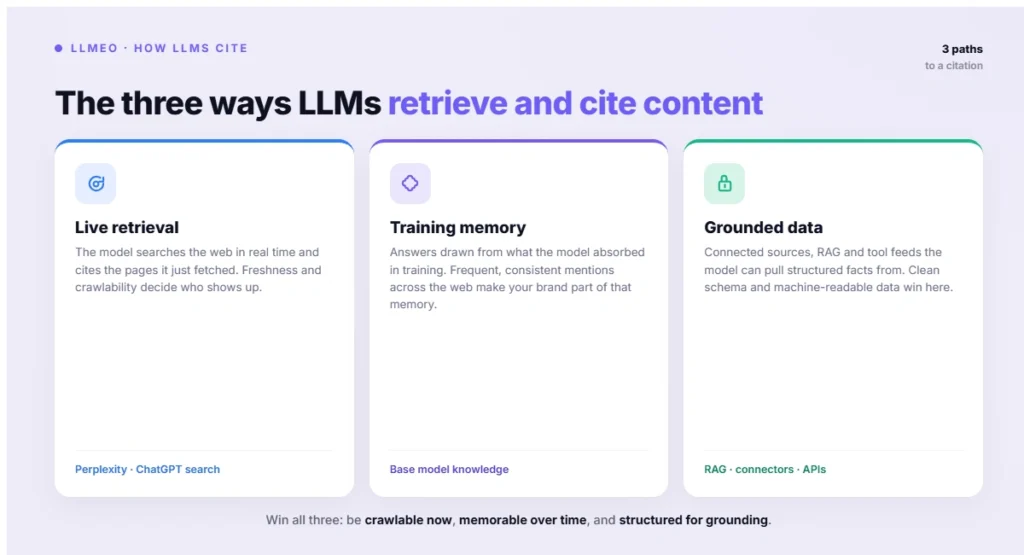
Figure 2: The three ways LLMs retrieve and cite content
4. The LLMEO Visibility Stack
Effective LLMEO works from the bottom up — skip a layer and the ones above it cannot deliver. Think of it as a stack.
- Layer 1 — Technical access. LLMs cannot cite what they cannot crawl. Allow AI bots in robots.txt, keep your sitemap current, and serve content in clean HTML (many AI crawlers do not execute JavaScript, so script-rendered content can be invisible to them).
- Layer 2 — Content structure. LLMs extract from machine-parsable content: clear H2/H3 hierarchy, a direct answer within the first 300 words, complete FAQ sections, and comparison tables for any multi-option topic.
- Layer 3 — Evidence & authority. Cite named sources for every statistic and claim — the Princeton research found citing sources lifts visibility by up to 40% — and add original data and expert quotes that give a model concrete, attributable material.
- Layer 4 — Off-page co-citation. Because models cross-reference, being mentioned consistently across many independent, trusted sources is decisive; co-citation across five or more independent sources is among the strongest off-page LLMEO signals.
- Layer 5 — Freshness. LLMs with web access heavily weight recency, so content without update dates or with stale statistics gets deprioritized — especially on freshness-focused platforms.

Figure 3: The LLMEO visibility stack — build from the bottom up
| 💡 Pro Tip Earn co-citations, not just backlinks. Getting your brand mentioned and accurately described across five or more independent, trusted sources — review sites, forums, reputable publications — does more for LLM visibility than almost any on-page change, because models cross-reference sources to decide what to trust. |
5. Technical Setup for AI Crawlers
The foundation of LLMEO is making sure AI systems can actually reach and read your content. Start by explicitly allowing the major AI crawlers in your robots.txt — including the bots used by OpenAI, Perplexity, Google and Anthropic — rather than leaving access to chance. Then make new and updated content retrievable fast: because some assistants’ live browsing runs on search indexes that can be slow to crawl passively, implementing the IndexNow protocol pushes your pages to those indexes within minutes instead of weeks, which matters for time-sensitive ChatGPT-style queries. IndexNow is available through common SEO plugins and CDN integrations.
Beyond access, two technical choices matter most. Serve content as clean, server-rendered HTML, since AI crawlers that do not run JavaScript will miss anything loaded by scripts. And add schema markup — BlogPosting, FAQPage, Article and Organization — to tell LLMs exactly what your content is, who wrote it, when it was updated, and which sections matter. These are unglamorous steps, but they are the difference between content that is eligible to be cited and content that is invisible to the systems doing the citing.
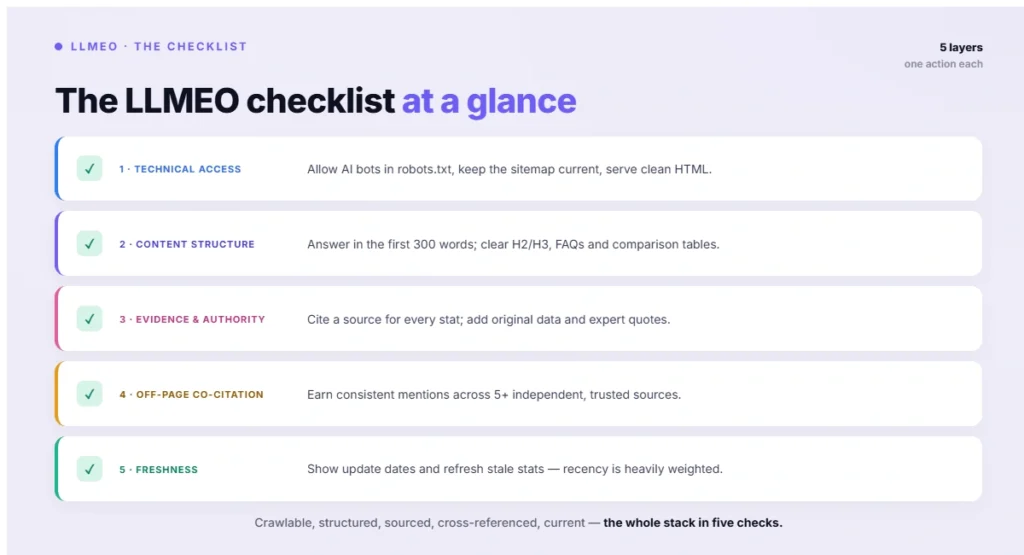
Figure 4: The LLMEO checklist at a glance
6. How to Measure LLMEO
Because there is no ranking position in an LLM, you measure share of voice — how often your brand appears across the prompts your audience would ask. Track that mention rate over time and compare it against competitors to know whether your efforts are working. Also track which of your pages get cited and how often, which reveals what content performs and what needs improvement. The simplest manual method is to query ChatGPT, Perplexity and Gemini directly with your audience’s real questions, document which sources appear, and repeat monthly to spot trends.
For systematic tracking, dedicated tools are essential, since traditional analytics cannot see AI citations. Specialized platforms monitor your mentions and share of voice across AI engines — we compare them in our guide to the best AI search monitoring tools and the wider category of answer engine optimization tools. Whichever method you use, treat changes as experiments: make a structural or authority improvement, then watch whether your mention rate rises. Note too that each model cites differently — studies show ChatGPT and Google share only about a third of their sources — so track the platforms that matter to your audience individually. The underlying models and their behaviors are covered in our best AI models guide.
| ⚠️ Important Be wary of vendors promising to “get you into ChatGPT” or “inject your brand into AI answers.” LLMEO is about building genuine authority and discoverability, not gaming the system. A simple rule: if you would not use a tactic for human readers, do not use it for LLMs — models increasingly detect and discount manipulation. |
7. Frequently Asked Questions
What is LLMEO?
LLMEO (large language model optimization) is the practice of optimizing your content, website and brand so large language models like ChatGPT, Claude, Gemini and Perplexity cite and recommend you in their answers. It focuses on the retrieval mechanisms LLMs use — RAG, embeddings and training data — and on building the authority that makes models trust your content.
Is LLMEO the same as GEO?
They are closely related and often used interchangeably. GEO (generative engine optimization) is the umbrella term for getting cited across all generative engines, while LLMEO emphasizes the language-model retrieval mechanics specifically. In practice the goals and tactics overlap heavily — both aim to make AI systems cite and recommend your content.
How do large language models choose what to cite?
LLMs with web access use retrieval-augmented generation: they run a real-time search, weight results for relevance, authority and recency, and synthesize an answer. They favor crawlable, well-structured, source-cited, fresh content that is corroborated across multiple trusted sites. Training data also plays a role but is hard to influence at typical scale.
How do I get my content cited by ChatGPT?
Make your content crawlable (allow AI bots, use IndexNow, serve clean HTML), structure it with clear headings and direct answers, cite named sources and add original data, earn consistent mentions across trusted third-party sites, and keep it fresh. Because ChatGPT’s web browsing relies on a search index, strong traditional SEO also feeds your visibility.
Does schema markup help with LLMEO?
Yes. Schema such as BlogPosting, FAQPage, Article and Organization tells LLMs exactly what your content is, who wrote it and when it was updated, making it easier to parse and trust. Combined with clean server-rendered HTML and clear structure, it improves your eligibility to be retrieved and cited.
How do I measure LLMEO success?
Measure share of voice — how often your brand appears across relevant prompts — rather than a ranking position, since LLMs are non-deterministic. Track which pages get cited and how often, query AI tools manually each month, and use specialized AI visibility platforms to monitor mentions across ChatGPT, Perplexity and Gemini over time.
Can I influence an LLM’s training data?
Theoretically yes, but only at massive scale and with unpredictable, uncontrollable results, so it is not a practical lever for most organizations. The realistic focus is the retrieval (RAG) path — being the fresh, authoritative, well-structured source that models pull from when they search the web in real time.
Is LLMEO worth it for my business?
For most businesses, yes. LLMs already influence how hundreds of millions of people find information, AI-referred visitors convert markedly better than organic ones, and LLM traffic is projected to rival traditional search in value soon. Building authority and crawlability now positions you before competitors lock in their share of AI citations.
8. Conclusion & Key Takeaways
LLMEO is how you earn a place inside the answers that ChatGPT, Claude, Gemini and Perplexity give to your audience. The work is foundational and honest: make your content crawlable, structure it for extraction, back claims with cited sources and original data, earn consistent mentions across trusted sites, and keep it fresh — then measure your share of voice rather than chasing a non-existent ranking. LLMEO is one layer of a complete strategy alongside generative engine optimization and answer engine optimization; together they make you visible across every way people now search. For platform specifics, see our Perplexity SEO guide.
- LLMEO earns brand mentions and citations inside LLM answers — success is a mention rate, not a ranking.
- The retrieval (RAG) path is the actionable lever; training-data influence is impractical for most.
- Build the stack bottom-up: technical access, structure, cited authority, off-page co-citation, freshness.
- Allow AI crawlers, use IndexNow, serve clean HTML, and add schema so models can read and trust you.
- Build genuine authority — avoid “inject me into ChatGPT” gimmicks — and measure share of voice over time.
LLMEO turns your content into the source AI assistants reach for — earned through crawlability, authority and consistency rather than tricks. Build the stack, earn the co-citations, measure your share of voice, and become the answer the models trust.
10 Comments
Pingback: Perplexity SEO: Complete Optimization Guide 2026
Pingback: 15 Best AI Sales Forecasting Tools 2026: Complete Guide
Pingback: 12 Best AI Tools for Academic Research 2026: Complete Guide
Pingback: Gong vs Chorus.ai 2026: Complete Comparison Guide
Pingback: 15 Best Answer Engine Optimization Tools 2026 Complete Guide
Pingback: LLMEO Strategies 2026: Complete Guide to LLM Optimization
Pingback: Best AI Chatbot for WordPress 2026 Tested
Pingback: Best Open Source AI Models 2026: DeepSeek vs Llama 4
Your 💫 passion for 🔥 helping others 🌟 shines through 💖 every single 🙏 post you share with us
Thank you for taking the time to share your thoughts! We truly appreciate the support and are glad you found value here. Stay connected—there’s more helpful content coming your way.