


The best local AI video generators compared — open-weight models you run on your own GPU for free, private, watermark-free video, with hardware needs and how to choose.
| $0 Cost per Clip (After Hardware) | 16GB Min VRAM (LTX-Video) | ~4 sec Fastest 5s Clip (RTX 4090) | 4 Serious Open Models | ComfyUI Go-To Interface |
| Quick answer: The best local AI video generators are open-weight models you download and run on your own GPU — no subscriptions, watermarks or content limits. LTX-Video is the fastest and runs on 16GB cards; Wan 2.2 (Alibaba) and HunyuanVideo (Tencent) are the quality leaders but want a 24GB GPU like an RTX 4090; and Mochi 1 is photorealistic but slow. Most people run them through ComfyUI, a free node-based interface. |
Key Takeaways
- LTX-2.3 (March 2026) added a rebuilt VAE, native synchronized audio, and 4K/50fps output — the first open model generating sound and video in one pass.
- HunyuanVideo 1.5 cut its parameters to 8.3B and its VRAM needs by ~40%, bringing the best-faces model down to 14 GB cards.
- NVIDIA’s NVFP4/FP8 optimizations (announced at CES 2026) promise up to 3× faster generation and ~60% less VRAM on RTX 40/50-series — landing in ComfyUI workflows now.
- Sora’s shutdown (April 2026) made the case for local generation better than any argument: cloud tools can vanish overnight; weights on your drive can’t.
Table of Contents
Table of Contents
1. What Is a Local AI Video Generator?
A local AI video generator is an open-weight model you download and run on your own hardware — typically a GPU — to create video from text or images, entirely offline. Unlike cloud services, there’s no per-generation fee, no watermark, no content filter, and your prompts never leave your machine. In practice “local” means models with publicly downloadable weights you can run yourself, whether or not the training pipeline is public, and on hardware you control rather than someone else’s servers.
What changed in 2025–2026 is that these models got good enough for real production work, not just experimentation. The quality gap with proprietary cloud tools has narrowed enough that self-hosting is now a legitimate architectural choice with real, understandable trade-offs. This guide ranks the leading local models and explains the hardware reality; it sits within our pillar guide to the best AI video generator tools, and pairs closely with our deeper dive on the best open source AI video generator options.
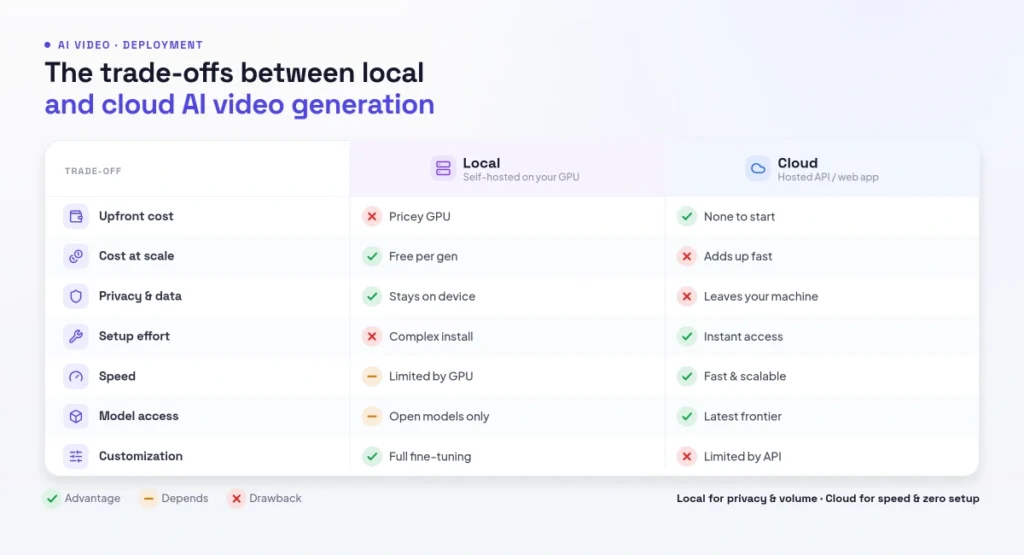
Figure 2: The trade-offs between local and cloud AI video generation
2. Why Run AI Video Generation Locally?
Four motivations drive the local-AI movement. Cost: after the hardware investment, every clip is free — no per-generation billing that adds up fast for heavy users. Privacy: your prompts, source images and outputs stay on your machine, which matters for sensitive or proprietary work. No restrictions: local models have no content filters or watermarks, giving full creative control. And customization: you can fine-tune, swap models, and use community add-ons in ways cloud services don’t allow.
The honest trade-off is ownership. What local models don’t come with is a polished UI, managed infrastructure, or someone else’s support queue — you own the setup, the updates and the debugging. For occasional, casual use, a cloud tool is simpler. But for high-volume creators, privacy-sensitive teams, or anyone who wants full control, the math increasingly favors local. The models powering this run on the same architectures discussed in our best AI models guide, just optimized for self-hosting.
It’s worth being clear-eyed about who local is actually for. If you make a handful of videos a month, the time you’d spend installing drivers, downloading multi-gigabyte weights and debugging node graphs will dwarf any savings — a cloud tool is the rational choice. Local pays off when generation volume is high enough that per-clip cloud fees become a real line item, when content can’t leave your environment for compliance reasons, or when you genuinely need to fine-tune models or use community extensions a hosted service won’t allow. Be honest about which camp you’re in before committing a weekend to setup; the right answer for a hobbyist is often different from the right answer for a studio running thousands of generations.
3. The Best Local AI Video Generators
Four open-weight models lead the local space in 2026, each with a clear niche. The table summarizes them, with detail below.
| Model | Best for | Note |
|---|---|---|
| LTX-Video (Lightricks) | Speed & lower VRAM | Near real-time; fits 16GB; Apache 2.0 |
| Wan 2.2 (Alibaba) | Best all-round quality | MoE architecture; runs on 24GB |
| HunyuanVideo (Tencent) | Realistic humans | 13B; best facial detail; higher VRAM |
| Mochi 1 (Genmo) | Photorealism | Apache 2.0; slow generation |
LTX-Video is the speed champion: it can generate a 5-second clip in roughly four seconds on an RTX 4090 — effectively real-time — and is the only top model that fits comfortably on a 16GB card. Its 2026 release added a rebuilt VAE, a larger text connector and native audio, and it carries a clean Apache 2.0 commercial-use license, making it the safest pick for commercial self-hosting. Wan 2.2 from Alibaba is the all-round quality leader, using a Mixture-of-Experts architecture that handles layout and detail with separate experts for a cinematic feel without raising inference cost; it runs on 24GB GPUs and has the most user-friendly community setup.
HunyuanVideo from Tencent is a 13-billion-parameter model with a dual-stream transformer that gives it class-leading instruction following and the best facial detail of any local model — the first choice for realistic human subjects, presenters or interview-style content. Its 1.5 release cut VRAM needs by 40%, bringing it onto 16GB GPUs, though it remains demanding. Mochi 1 from Genmo delivers excellent photorealism with strong prompt alignment under an Apache 2.0 license, but it’s slow — best reserved for when quality matters more than turnaround. Lighter or older options like CogVideoX and Stable Video Diffusion suit limited hardware or learning workflows, with SVD’s large LoRA library enabling diverse styles.
One pattern worth understanding is the architectural divergence behind these models. Wan 2.2’s Mixture-of-Experts approach splits the work between specialized sub-networks, so it can scale capacity without a proportional jump in the compute each clip costs — which is part of why it balances quality and accessibility so well. HunyuanVideo’s dual-stream design processes text and video tokens independently before fusing them, which is exactly what gives it such strong prompt adherence and facial fidelity. LTX-Video, by contrast, is engineered around an efficient pipeline that prioritizes throughput, trading a little peak quality for dramatic speed. You don’t need to grasp the math to benefit from this, but knowing each model’s design philosophy explains why they excel at different things — and helps you predict which will suit a given project before you spend an evening downloading weights.

Figure 3: The four leading local video models and their niches
4. Hardware Requirements: The Reality
Hardware is the make-or-break factor for local video. VRAM (your GPU’s memory) determines what you can run at all. LTX-Video fits comfortably on a 16GB card, while Wan 2.2, HunyuanVideo and Mochi 1 really want 24GB — an RTX 4090, 3090 or A6000 — or aggressive multi-GPU sharding. Smaller or quantized variants can squeeze onto 12–16GB GPUs with some compromise.
Speed scales with the card. On an RTX 4090, LTX-Video produces a clip in around 90 seconds, Wan 2.2 in about 4.5 minutes, HunyuanVideo in roughly 6 minutes, and Mochi 1 in about 8 minutes. Halve those speeds on a 3090, and expect several times longer on a 12GB card like a 3060 (LTX can still run, but slowly). If you lack a powerful GPU, renting cloud GPUs (such as A100, H100 or RTX A6000 instances) is a middle path — you self-host the model without owning the hardware. The table below summarizes the practical picture.
| Model | Min VRAM | ~Clip time (RTX 4090) |
|---|---|---|
| LTX-Video | 16GB | ~90 seconds |
| Wan 2.2 | 24GB | ~4.5 minutes |
| HunyuanVideo | 16–24GB | ~6 minutes |
| Mochi 1 | 24GB | ~8 minutes |
| 💡 Pro Tip If you’re new to local video, start with LTX-Video on whatever 16GB+ GPU you have. Its near-real-time speed means fast iteration, so you learn prompt patterns and ComfyUI workflows in minutes rather than waiting 8 minutes per attempt. Once you’ve outgrown it and understand the workflow, graduate to Wan 2.2 or HunyuanVideo on a 24GB card for higher quality. Learning on a slow model is needlessly painful. |
5. Local AI Video Generator VRAM Requirements (July 2026)
| Model | Full Quality (FP16) | Quantized (FP8/GGUF) | Minimum GPU (quantized) | Recommended GPU | Output |
|---|---|---|---|---|---|
| Wan 2.2 (1.3B) | ~8 GB | 4–6 GB | RTX 3060 (8 GB) | RTX 4070 | 480p, best quality-per-VRAM on budget cards |
| Wan 2.2 (14B) | ~54 GB | 6–8 GB at 480p (GGUF Q4), 16–24 GB for quality | RTX 4080 (16 GB) | RTX 4090 / 3090 (24 GB) | Highest overall quality, cinematic |
| HunyuanVideo 1.5 (8.3B) | ~47 GB | ~8–16 GB with offloading | RTX 4070 Ti (16 GB, comfortable at 14 GB+) | RTX 4090 | 720p, best faces & physics |
| LTX-Video 2.3 | ~20 GB (32 GB official for 4K) | 6–8 GB with FP8 + tiling | RTX 3060 (8–12 GB) | RTX 4090 (native 4K + audio) | Fastest — near real-time, native audio |
| CogVideoX (5B) | ~16 GB | ~8 GB (FP8, 2B variant) | RTX 3060 (12 GB) | RTX 4070 Ti | 480p, best prompt-following |
| Mochi 1 | 24 GB+ | ~20 GB (FP8) | RTX 3090 (24 GB) | RTX 4090 | High quality but slow; Apache 2.0 |
The short version: 8 GB gets you started (Wan 1.3B, LTX with tiling), 16 GB is the comfortable minimum for production-quality 720p, and 24 GB (RTX 4090/3090) is the sweet spot where every model on this list fits. The RTX 5090’s 32 GB removes quantization compromises entirely. Plan for at least 16 GB of system RAM too — text-encoder offloading needs it.
6. Interfaces & Getting Started
A model is only half the equation — you also need an interface to load, configure and run it. ComfyUI is the definitive interface for local AI video generation: its node-based visual workflow system supports every major open-source video model through community-developed nodes, giving you one unified environment regardless of which model you’re using. It’s free, powerful, and where most of the local-video community works and shares workflows.
Getting started typically means installing ComfyUI, downloading a model’s weights (often from Hugging Face), placing them in the right folder, and loading a community workflow. There’s a learning curve — node graphs feel unfamiliar at first — but the payoff is total control over every stage of generation. Most models are text-to-video, though several (LTX-Video, CogVideoX, and an experimental Wan 2.2 workflow) support image-to-video, which overlaps with our guide to the best free AI image to video generator tools. For developers who’d rather call an API than manage a GPU, hosted endpoints exist too — see our best AI API guide.
7.How Fast Is Each Model? (5-second clip, typical settings)
| Model | RTX 4090 | Notes |
|---|---|---|
| LTX-Video 2.3 | ~4 seconds | Effectively real-time; distilled pipeline |
| Wan 2.2 (1.3B) | ~3 minutes | 480p |
| Wan 2.2 (14B) | 4–15 minutes | Slowest, highest quality |
| HunyuanVideo 1.5 | several minutes at 720p | 1.87× faster than v1.0 thanks to sparse attention |
| CogVideoX (5B) | ~3–5 minutes | 480p, 49 frames |
Times vary with step count (20–50), resolution, and quantization. Tip: generate at 480/720p, then upscale with Real-ESRGAN and interpolate frames with RIFE — doubles perceived quality at minimal compute cost.
8. How to Choose: Local vs Cloud
The decision comes down to hardware, volume and priorities. Choose local if you generate a lot of video (so per-clip cloud costs would mount), need privacy or unrestricted content, want full customization, and have — or can rent — a capable GPU. Choose cloud if you generate occasionally, want the absolute highest cinematic quality with zero setup, or lack the hardware and don’t want to manage it. Many creators use both: local for iteration and bulk work, cloud for hero shots.
Within local, match the model to your hardware and goal: LTX-Video for low VRAM and fast iteration, Wan 2.2 for the best balance on a 24GB card, HunyuanVideo when realistic humans matter most, and Mochi 1 when photorealism outweighs speed. Note that top proprietary cloud options like Veo and Runway are covered in our pillar — and a reminder that OpenAI’s Sora consumer app was discontinued, so it’s not a path to rely on. For platform-specific advice, see our guides to the best AI video generator for YouTube and the best AI tools for generating images for still assets.
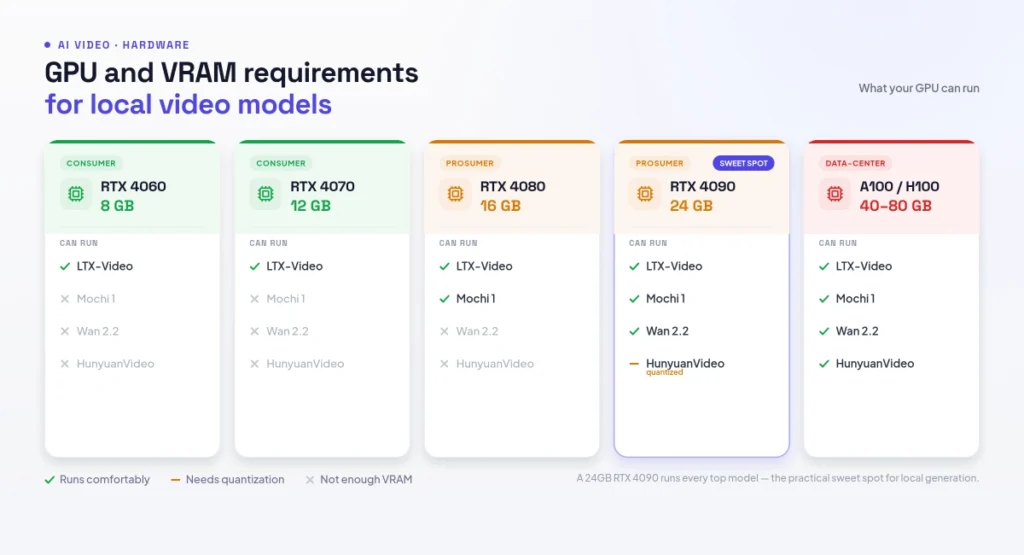
Figure 4: GPU and VRAM requirements for local video models
| ⚠️ Important “Open weights” does not always mean “free for commercial use.” Licenses vary — Mochi 1 and LTX-2 use the permissive Apache 2.0, but other models carry restrictions on commercial output, training data, or regional use. Before using local-generated video in a paid project, read the specific model’s license carefully. Assuming all open models are commercially safe is a common and costly mistake. |
9. Frequently Asked Questions
What is the best local AI video generator?
It depends on your hardware and goal. LTX-Video is best for speed and lower VRAM (runs on 16GB, near real-time). Wan 2.2 offers the best all-round quality on a 24GB card. HunyuanVideo leads for realistic human subjects but is more demanding. Mochi 1 is great for photorealism but slow. There’s no single winner — match the model to your setup.
Can I run AI video generation on my own computer?
Yes, if you have a capable GPU. LTX-Video runs on a 16GB card, while quality leaders like Wan 2.2 and HunyuanVideo want 24GB (an RTX 4090, 3090 or A6000). Smaller or quantized variants can fit on 12–16GB with compromises. If you lack the hardware, you can rent cloud GPUs and self-host the model that way.
Is local AI video generation free?
The models are free to download and run, so there’s no per-clip cost once you’re set up — a big saving for heavy users versus per-generation cloud billing. The real cost is hardware (a 16–24GB GPU) and electricity, plus your time for setup and maintenance. There are also no subscription fees or watermarks.
What GPU do I need for local AI video?
For comfortable use, a 24GB GPU like an RTX 4090, 3090 or A6000 runs the quality leaders (Wan 2.2, HunyuanVideo, Mochi 1). A 16GB card handles LTX-Video well and some quantized variants of others. 12GB cards like a 3060 can run LTX-Video but slowly. More VRAM means more model choice and faster generation.
What software do I use to run local video models?
ComfyUI is the definitive interface — a free, node-based visual workflow tool that supports every major open-source video model through community nodes. You install ComfyUI, download a model’s weights (usually from Hugging Face), load a community workflow, and generate. There’s a learning curve, but it gives complete control over the pipeline.
Are local AI video models as good as cloud tools?
The gap has closed significantly. Top local models like Wan 2.2 and HunyuanVideo rival or beat older cloud models in independent evaluations, and self-hosting is now a legitimate production choice. The very highest cinematic quality still tends to come from proprietary cloud models, but for most work, local output is more than good enough.
Can local models do image-to-video?
Yes, several do. LTX-Video has a built-in image-to-video mode, CogVideoX has a dedicated image-to-video variant, and HunyuanVideo offers an image-to-video version. Wan 2.2 added an experimental image-to-video workflow, though it was still rough as of early 2026. Image-to-video animates a still image, while text-to-video generates motion from a prompt.
Is local-generated AI video safe to use commercially?
It depends on the model’s license. Mochi 1 and LTX-2 use the permissive Apache 2.0, which allows commercial use, but other models carry restrictions on commercial output, training data or regional use. Always read the specific license before using local-generated video in a paid project, since open weights don’t automatically mean commercial freedom.
10. Conclusion & Key Takeaways
Local AI video generation has matured from a researcher’s curiosity into a real production option. Open-weight models you run on your own GPU give you free clips, full privacy, no watermarks and total creative control — at the cost of owning the setup. LTX-Video is the fast, accessible starting point on a 16GB card; Wan 2.2 and HunyuanVideo are the quality leaders for 24GB rigs; and Mochi 1 brings photorealism when you can spare the time. Run them through ComfyUI, mind the per-model licenses, and you have a powerful, self-hosted video studio. To go deeper, see our pillar on the best AI video generator tools and the guide to the best open source AI video generator models.
- Local video generators are open-weight models you run on your own GPU — free per clip, private, watermark-free.
- LTX-Video (speed, 16GB), Wan 2.2 and HunyuanVideo (quality, 24GB), Mochi 1 (photorealism, slow).
- You need a capable GPU (16–24GB) or rented cloud GPUs; ComfyUI is the standard interface.
- The quality gap with cloud has closed — self-hosting is now a real production choice.
- Check each model’s license before commercial use; open weights don’t always mean commercial-free.
Local AI video puts a full generation studio on your own machine — no subscriptions, no watermarks, no limits. Start with LTX-Video to learn the ropes, scale up to Wan 2.2 or HunyuanVideo for quality, and own your creative pipeline end to end.
11 Comments
Pingback: Best Open Source AI Video Generator 2026 - Techiehub
The breakdown of the cost savings compared to cloud solutions is a game-changer, especially with the 71% figure you highlighted for long-term projects. I also found the section on hardware tiers particularly helpful for setting realistic expectations before diving into ComfyUI workflows. Thanks for the comprehensive guide on maintaining full creative control without the monthly subscription bills.
Really thorough breakdown of local AI video generators! For anyone who prefers a cloud-based option without needing to run models locally, HappyHorse AI Video is worth a look — it’s a free online tool that generates cinematic short videos from text prompts or images. Supports 1080P output, natural character generation, and smooth camera motion. No local setup required, and the free plan includes starter credits. Great complement to the local options you’ve covered here.
Useful benchmark! Worth noting that local models have the privacy advantage but the compute requirements are still steep for most users. For teams without high-end GPUs, cloud-based alternatives have gotten competitive on quality — especially for text-to-video — while keeping iteration cycles fast. The local vs. cloud tradeoff is less about quality now and more about your hardware budget.
The breakdown between hardware requirements and workflow choices was especially useful because people often underestimate how much iteration speed changes the creative process. The comparison between rapid experimentation and quality-focused pipelines highlights a real tradeoff creators run into once they move from testing prompts to producing content consistently.
Recently I started learning more about coin collecting.
I was looking for coin values, but many resources were outdated.
While researching I discovered https://groshi.xyz
The site provides useful guides about coin values.
I found the information quite useful.
Pingback: 10 Best AI Tools for Generating Images in 2026-27
Pingback: Best AI Video Generator to Create Stunning Videos Fast
Pingback: Best Open Source AI Video Generator You Can Use Free
Pingback: Best Free AI Image to Video Generator Worth Trying
Pingback: Best AI Video Generator for YouTube to Grow Faster