


A practical, up-to-date guide to the best AI models — the current frontier leaders, how they compare on coding, reasoning and writing, what they cost, and how to pick (and combine) the right model for your use case.
| 4 Frontier Flagship Models | 61.4 Top Intelligence Index Score | 1M+ Max Context Window (Tokens) | $2/$12 Best Price-Performance (per M) | 300+ Models Benchmarked |
| Quick answer: The best overall AI model right now is Claude Opus 4.8, which tops the Artificial Analysis Intelligence Index, followed by GPT-5.5, Gemini 3.1 Pro and Grok 4.3. There is no single winner for everyone — match the model to the task: Claude for coding and writing, Gemini for reasoning and price-to-performance, GPT-5.5 for creative work, and open models like Llama 4 or DeepSeek for low-cost, high-volume jobs. |
Key Takeaways
- Claude Opus 4.8 is the current overall leader; GPT-5.5, Gemini 3.1 Pro and Grok 4.3 complete the frontier lineup.
- There is no single “best” — match the model to the task: Claude (coding/writing), Gemini (reasoning/value), GPT-5.5 (creative), open models (cost).
- Frontier API pricing ranges from about $0.10 to $75 per million tokens — choose by price-to-performance, not just the top of the leaderboard.
- Build model-agnostic: leaderboards change monthly, so route between models and avoid hardcoding a single provider.
Table of Contents
1. The Frontier AI Models at a Glance (July 2026)
| Model | Intelligence Index (AA) | Price per 1M tokens (in/out) | Context | Best For |
|---|---|---|---|---|
| Claude Fable 5 | 60 — #1 overall | Premium tier (via Claude paid plans/API) | 1M | Hardest coding & agentic work (80.3% SWE-Bench Pro) |
| Claude Opus 4.8 | 56 | $5 / $25 | 200K+ | Everyday frontier pick; top-tier coding & long-form |
| GPT-5.5 | 55 | $5 / $30 (doubled from GPT-5.4) | 272K std | Daily chat, knowledge work, largest ecosystem |
| Claude Sonnet 5 | 53 | $2 / $10 intro until Aug 31 (then $3/$15) | 1M | Best value at the frontier; writing & instruction-following |
| Gemini 3.1 Pro | ~57* | $2 / $12 (doubles past 200K) | 1M | Hardest-mode reasoning & accuracy |
| Gemini 3.5 Flash | 55 | $1.50 / $9 | 1M | Best price-performance; bulk content |
| Grok 4.3 | competitive | $1.25 / $2.50 | 1M | Real-time X/web data; cheapest Tier-1 reasoning |
| Grok 4.1 Fast | — | $0.20 / $0.50 | — | Cheapest frontier API by far (~1/15th of GPT-5.5) |
| DeepSeek V4-Flash | — | $0.14 / $0.28 | 1M | Cheapest open-weight with 1M context |
*Benchmark sources vary by methodology — scores from Artificial Analysis Intelligence Index v4.1 and vendor-reported results; always dated July 2026.
2. What Changed in July 2026:
- Claude Fable 5 returned July 1 after an 18-day suspension under a US export-control order — the first frontier model ever switched off and back on by regulators. It reclaims #1 on the Intelligence Index (60).
- Claude Sonnet 5 launched June 30 as the new claude.ai default — introductory API pricing of $2/$10 runs until August 31, making it the value pick at the frontier.
- GPT-5.5’s price doubling settled in — at $5/$30 it now costs more than Gemini for flagship inference, reshaping high-volume API economics.
- Watch next month: GPT-5.6 (Terra/Sol variants) is in staged rollout.
3. What Makes an AI Model “the Best”?
Ask “what is the best AI model?” and the honest answer is “best at what?” The frontier models are now so capable that the interesting differences are no longer about raw intelligence alone — they are about which model is strongest for a specific job, at a specific price, with the right speed and context window. A model that writes beautifully may not be the cheapest for high-volume work; the best reasoner may not be the best coder. Choosing well means knowing the dimensions that actually matter.
Six criteria separate the leaders. Intelligence (general reasoning, measured by composite indexes and benchmarks like GPQA Diamond) tells you raw capability. Coding ability (SWE-bench and real GitHub issue resolution) matters enormously for developers. Reasoning and math (AIME, GPQA) matter for analysis and research. Speed (tokens per second and latency) matters for real-time products. Context window (how much text a model can consider at once) matters for long documents. And price (cost per million input and output tokens) determines what is affordable at scale. The “best” model is whichever balances these for your use case.
It also helps to understand what these models are under the hood. Today’s leading models are large language models (LLMs) — giant neural networks trained on vast datasets to predict and generate text, and increasingly to handle images, audio and video too. If you want the foundational explainer before going further, see our guide to what an LLM is and the broader context of generative AI. With the criteria in hand, here is how the current frontier stacks up.
One more thing worth setting straight: benchmarks are useful but imperfect. A composite “intelligence index” rolls up dozens of tests into one number, which is handy for a quick ranking but hides the fact that models trade blows test by test. A model can lead on graduate-level science questions yet trail on real-world coding, or post a brilliant math score while writing flat prose. Treat published scores as a starting filter, not a verdict — the model that wins a leaderboard is not automatically the model that will win on your documents, your codebase or your customers. The sections below translate the headline numbers into practical, task-by-task guidance you can actually act on.
4. The Top AI Models Right Now
The labs ship new flagships every few weeks, and the leaderboard changes hands often, but a clear frontier group has emerged. The four models worth comparing at the top are Anthropic’s Claude Opus 4.8, OpenAI’s GPT-5.5, Google’s Gemini 3.1 Pro, and xAI’s Grok 4.3 — with a strong supporting cast of open and value models behind them.
What is striking about the current frontier is how close it is. The top models are separated by a few points on most composite indexes, which means the practical decision rarely comes down to “which is smartest” — they are all extremely capable — and instead to which one fits your task, budget and ecosystem. Each lab has also developed a recognizable personality: Anthropic’s Claude is the coding and writing specialist, OpenAI’s GPT is the versatile all-rounder with the deepest ecosystem, Google’s Gemini is the multimodal reasoning-and-value play, and xAI’s Grok is the lean, agentic, cost-conscious option. Keep those identities in mind as you read the profiles below; they are a faster guide to a good default than any single benchmark number.
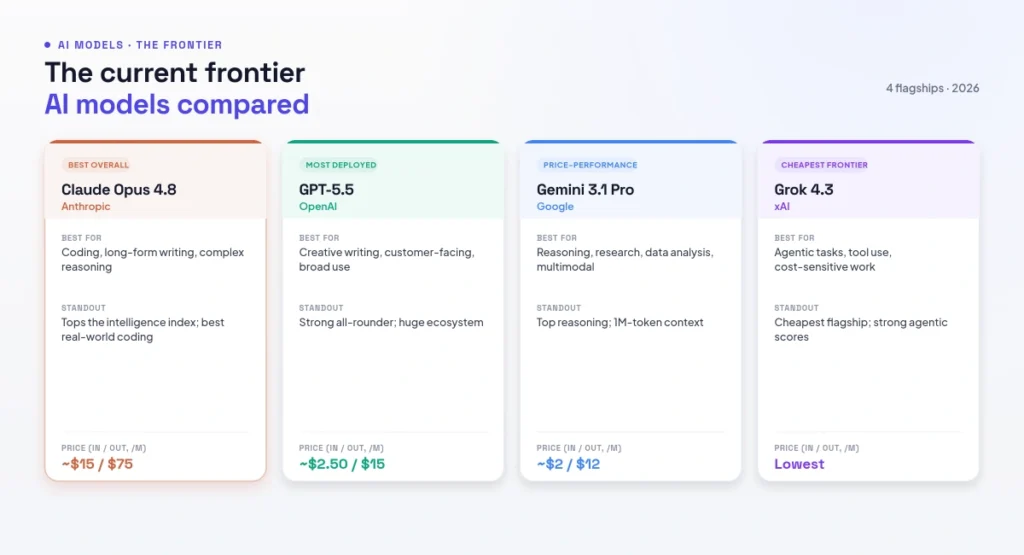
Figure 2: The current frontier AI models compared
4.1 Claude Opus 4.8 — Best Overall & Best for Coding/Writing
| Developer | Anthropic |
| Best For | Coding, long-form writing, complex reasoning |
| Standout | Tops the Artificial Analysis Intelligence Index; leads real-world coding benchmarks |
| Pricing (Opus) | ~$15 in / $75 out per million tokens (Sonnet tier ~$3 / $15) |
Claude Opus 4.8 is the current overall leader, topping the headline intelligence index and leading on real-world coding — resolving complex GitHub issues better than its rivals — while producing long-form writing many reviewers consider the best available. It powers popular developer tools and is the workhorse for serious coding and editorial work. The mid-tier Claude Sonnet delivers most of that quality at a fraction of the cost. For the full picture, see our dedicated guide to Claude AI. The trade-off is price: Opus is among the most expensive frontier models per token.
4.2 GPT-5.5 — Best for Creative & Customer-Facing Work
| Developer | OpenAI |
| Best For | Creative writing, customer-facing responses, broad general use |
| Standout | Strong all-rounder; second on the intelligence index; huge ecosystem |
| Pricing | ~$2.50 in / $15 out per million tokens (Pro tier far higher) |
GPT-5.5 is OpenAI’s current flagship and the most widely deployed frontier model, sitting just behind Claude on overall intelligence and leading on creative writing. Its enormous ecosystem, tooling and brand make it the default choice for many teams and the model behind countless products. It is neck-and-neck with Claude at the top for coding, and its mid-range pricing makes it a practical all-rounder. Many of the best AI tools like ChatGPT are built on this family.
4.3 Gemini 3.1 Pro — Best Reasoning & Price-to-Performance
| Developer | |
| Best For | Reasoning, research synthesis, data analysis, multimodal |
| Standout | Top reasoning scores; 1M-token context; best frontier price-to-performance |
| Pricing | ~$2 in / $12 out per million tokens |
Gemini 3.1 Pro is the price-to-performance champion at the frontier, posting the highest reasoning scores (including a leading GPQA Diamond result) while costing less than its rivals. It accepts text, images, audio, video and code in a single one-million-token context window, making it exceptional for research synthesis and long-document or data-analysis work. For teams that want frontier reasoning without frontier pricing, it is often the smart default.
4.4 Grok 4.3 — Cheapest Frontier & Strong Agentic Use
| Developer | xAI |
| Best For | Agentic tasks, tool use, cost-sensitive frontier work |
| Standout | Cheapest of the four flagships; strong tool-use and agentic scores; very large context |
| Pricing | Lowest of the frontier flagships |
Grok 4.3 rounds out the frontier as the most affordable of the four flagships, with strong agentic and tool-use performance and a notably large practical context window. It is a sensible pick when you want frontier-class capability for agent workflows or high-volume tasks without the top-tier price tag.
4.5 Open & Value Models — Llama 4, DeepSeek, Qwen
Beyond the proprietary frontier, open-weight models have become genuinely competitive. Meta’s Llama 4 family is free to download and self-host; DeepSeek’s models offer near-frontier performance at a fraction of the API cost; and Qwen, GLM and Kimi round out a strong open ecosystem. For high-volume, cost-sensitive or privacy-sensitive workloads, these are often the right answer — you trade some peak capability for dramatic savings and control.
The gap between open and closed has narrowed faster than many expected. A year or two ago, open models trailed the frontier by a wide margin; today the best open weights match proprietary models on a growing list of everyday tasks, and they can be accessed cheaply through hosted APIs if you do not want to run them yourself. The strategic appeal is real: no per-token lock-in, full control over data, the ability to fine-tune freely, and protection against a provider changing prices or deprecating a model you depend on. The catch remains the very top of the capability curve and the operational burden of self-hosting — but for an increasing share of production workloads, an open model is not a compromise, it is the sensible default.
5. Best AI Model by Use Case
The most useful way to choose is by job. The table below maps common needs to the model that tends to win today.
| Use Case | Best Pick | Why |
|---|---|---|
| Coding | Claude Opus 4.8 / GPT-5.5 | Lead real-world coding benchmarks; power top dev tools |
| Long-form writing | Claude Opus 4.8 | Best prose quality; large single-pass output |
| Reasoning & analysis | Gemini 3.1 Pro | Highest reasoning scores; 1M-token context |
| Creative writing | GPT-5.5 | Leads creative benchmarks; flexible style |
| Agentic / tool use | Grok 4.3 / Claude | Strong tool-use; cost-effective for agents |
| Budget / high volume | DeepSeek / Gemini Flash | Frontier-ish quality at a fraction of the cost |
| Self-hosted / private | Llama 4 | Open weights; run on your own infrastructure |
The pattern that separates effective teams from frustrated ones is routing: using different models for different tasks rather than forcing one model to do everything. A common setup is Claude for code reviews, Gemini for research synthesis, GPT-5.5 for customer-facing responses, and a cheap open model for high-volume background work. Getting strong results from any of them also depends on how you prompt — see our guide to prompt engineering.
It is also worth remembering that “use case” includes more than the task type — it includes your constraints. A startup shipping a consumer app on a tight budget will weigh price and speed far more heavily than a research team chasing the hardest reasoning problems. A regulated enterprise will prioritize data handling over a one-point benchmark edge. A solo creator may care most about writing quality and ease of use. The same task can have a different “best model” depending on who is doing it and why, which is exactly why a rigid one-model policy underperforms a flexible, per-task choice. Start from your real constraints, then let the use-case table above point you to a sensible default.

Figure 3: The best AI model for each common use case
6. Proprietary vs Open-Source Models
One of the biggest decisions is proprietary versus open. Proprietary models (Claude, GPT, Gemini, Grok) are accessed through an API, deliver peak capability, and require no infrastructure — but you pay per token, send your data to a third party, and depend on the provider’s roadmap and uptime. Open-weight models (Llama, DeepSeek, Qwen) can be downloaded and run on your own hardware, giving you control, privacy and zero per-token API cost — but you take on the cost and complexity of running them, and the very top of the capability curve still belongs to the proprietary frontier.
For most teams the answer is a blend. Use a proprietary frontier model where peak quality matters (complex coding, customer-facing answers, hard reasoning) and an open or value model for high-volume, cost-sensitive or privacy-sensitive work. The economics are compelling: open and value models can cost a fraction of frontier API rates, and for many routine tasks the quality gap is small enough that the savings dominate. The key is to measure quality on your actual tasks rather than assuming the most expensive model is always worth it.
Data handling often decides the question on its own. If you operate in a regulated industry, or you simply do not want sensitive prompts leaving your environment, a self-hosted open model gives you guarantees a third-party API cannot. Proprietary providers do offer enterprise tiers with stronger data commitments, no-training guarantees and compliance certifications, which satisfy many organizations — but the only way to be certain your data never leaves your infrastructure is to run the model yourself. Weigh that against the engineering cost of hosting: GPUs, scaling, uptime and model updates all become your responsibility. For many companies the pragmatic path is a frontier API for hard tasks under a strict data agreement, plus a self-hosted open model for anything involving truly sensitive information.
7. Understanding Model Specs
A few specs come up constantly, and understanding them makes comparisons much clearer. The context window is how much text (measured in tokens, roughly ¾ of a word each) a model can consider at once; bigger windows — now up to a million tokens or more — let you feed in long documents, codebases and conversation history. Parameters are the internal values a model learned during training; more can mean more capability, but architecture and training quality matter more than raw count. Multimodality is whether a model handles images, audio and video in addition to text. And pricing is quoted per million input and output tokens, with output usually costing several times more than input.
Two related concepts often confuse newcomers: fine-tuning and retrieval. Fine-tuning further trains a model on your own data to specialize its behavior, while retrieval-augmented generation (RAG) feeds relevant documents into the model at query time so it can answer from your knowledge base without retraining. They solve different problems and are often combined; our guide to fine-tuning vs RAG breaks down when to use each. Knowing these terms helps you read model documentation and choose the right approach for grounding a model in your own information.
Finally, note that each flagship comes in a family of tiers, and choosing the right tier matters as much as choosing the right brand. Providers typically offer a top “opus/pro” tier for the hardest work, a balanced mid tier (Sonnet, GPT mid, Gemini Flash) that delivers most of the quality for a fraction of the price, and a tiny “haiku/mini/lite” tier built for speed and volume. For a great deal of real-world work — classification, extraction, simple drafting, routing — the mid or small tier is the correct choice, not the flagship. A frequent and costly mistake is defaulting every call to the most powerful tier; matching the tier to the difficulty of the task is one of the easiest ways to cut your AI bill without hurting results.
8. Pricing Comparison
Pricing spans a huge range, from frontier flagships to ultra-cheap value tiers. The table below shows representative API rates per million tokens (input / output); always confirm current rates on the provider’s site, as they change frequently. A useful rule of thumb when budgeting: a million tokens is roughly 750,000 words, so a model at $15 output per million tokens costs about two cents per 1,000 words generated — cheap for a single document, but a figure that adds up quickly across millions of automated calls, which is exactly why tier and model choice matter so much at scale.
| Model | Developer | Price (in / out per M tokens) | Best For |
|---|---|---|---|
| Claude Opus 4.8 | Anthropic | ~$15 / $75 | Top-end coding & writing |
| Claude Sonnet | Anthropic | ~$3 / $15 | Most quality per dollar (Claude) |
| GPT-5.5 | OpenAI | ~$2.50 / $15 | All-round flagship |
| Gemini 3.1 Pro | ~$2 / $12 | Best price-to-performance | |
| Gemini Flash-Lite | ~$0.10 / $0.40 | Cheapest proprietary, high volume | |
| DeepSeek V3 | DeepSeek | ~$0.27 / $1.10 | Budget near-frontier |
| Llama 4 | Meta | Free (self-host) | Private / self-hosted |
9. How to Choose (and Combine) Models
Choosing a model is less about finding one winner and more about building a sensible default plus a routing plan. Start by identifying your primary task and picking the model that leads it: coding leans Claude or GPT-5.5, reasoning leans Gemini, creative leans GPT-5.5, and cost-sensitive volume leans an open or Flash-tier model. Then set a budget ceiling and check whether a cheaper tier meets your quality bar on a sample of real work — frequently it does.
The most resilient approach is to stay model-agnostic. Because new flagships ship every few weeks and the leaderboard changes hands monthly, applications hardcoded to a single provider face repeated migration work. Build your stack so you can swap models cheaply — route each task to the best model for it, keep prompts portable, and treat the model layer as a commodity you can upgrade. That way you capture the benefit of every new release without rebuilding, and you are never trapped by one provider’s pricing or outages.
Finally, remember that the model is only part of the system. How you prompt it, whether you ground it in your own data with RAG, and how you handle its errors often matter more than which flagship you pick. A well-prompted, well-grounded mid-tier model frequently beats a poorly-used frontier one — which is why the teams that win invest as much in their workflow as in their model choice.
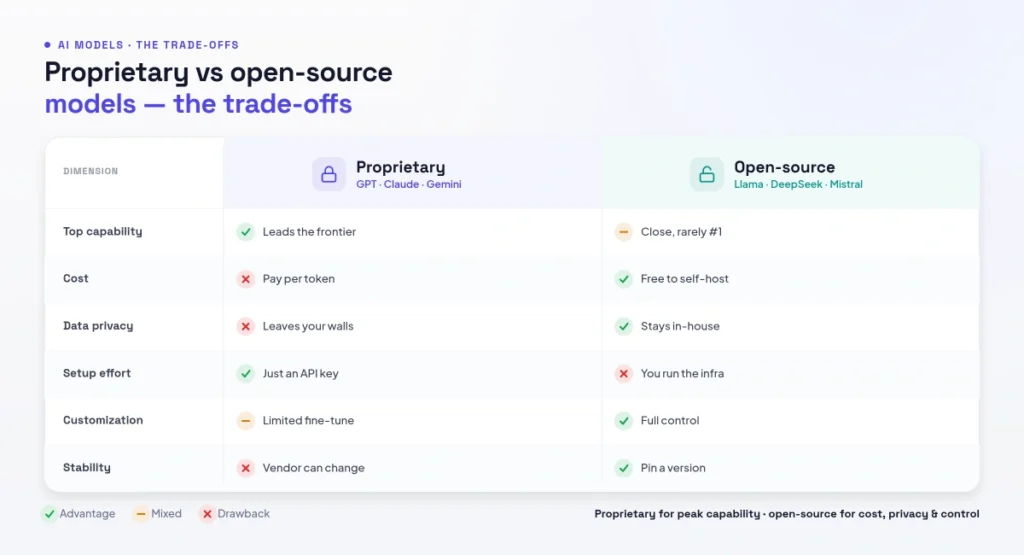
Figure 4: Proprietary vs open-source models — the trade-offs
10. Limitations to Keep in Mind
Even the best models share important limitations. The most consequential is hallucination: every model can produce confident, fluent statements that are factually wrong, because they generate plausible text rather than retrieve verified facts. Our guide to AI hallucinations explains why and how to mitigate it. Models also reflect biases in their training data, have a knowledge cutoff unless connected to live search, and can be inconsistent — the same prompt can yield different answers. Benchmarks, too, are imperfect proxies; a model that tops a leaderboard may not be best on your specific tasks, which is why testing on your own work beats trusting rankings alone.
There are practical limits too. Frontier models can be slow and expensive for high-volume use, which is why routing cheaper models to easy tasks matters. They have context limits — even a million-token window fills up, and quality can degrade on information buried in the middle of very long inputs. And they depend on how you use them: a vague prompt, missing context, or no grounding in your own data will produce weak results from even the strongest model. None of these are reasons to avoid frontier AI; they are reasons to design the surrounding system thoughtfully — good prompts, retrieval for facts, cheaper models for easy work, and human review where it counts — so the model’s strengths show and its weaknesses are contained.
| ⚠️ Important AI model rankings change constantly — new flagships launch every few weeks and leadership shifts month to month. Treat any “best model” claim, including this one, as a snapshot, verify the current version and pricing on the provider’s site, and benchmark candidates on your own tasks before standardizing on one. |
11. Frequently Asked Questions
What is the best AI model right now?
The best overall AI model is currently Claude Opus 4.8, which tops the Artificial Analysis Intelligence Index, followed closely by GPT-5.5, Gemini 3.1 Pro and Grok 4.3. The best choice for you depends on the task — Claude for coding and writing, Gemini for reasoning and value, GPT-5.5 for creative work.
What is the best AI model for coding?
Claude Opus 4.8 and GPT-5.5 are neck-and-neck at the top for coding, with Claude leading on real-world GitHub issue resolution. Both power the developer tools most professionals use. For budget coding at scale, DeepSeek and Gemini’s cheaper tiers offer strong value.
Which AI model is the cheapest?
Among proprietary models, Gemini’s Flash-Lite tier is among the cheapest at roughly $0.10/$0.40 per million tokens, and DeepSeek V3 is very affordable at about $0.27/$1.10. Open-weight models like Llama 4 are free to download but require your own GPU infrastructure to run.
Are open-source AI models as good as proprietary ones?
They are close for many tasks but not at the very top. Open models like Llama 4 and DeepSeek deliver near-frontier performance at a fraction of the cost and give you privacy and control, but the absolute peak of capability still belongs to proprietary frontier models. For high-volume or private work, open models are often the better choice.
What is a context window and why does it matter?
A context window is how much text a model can consider at once, measured in tokens (roughly ¾ of a word each). Larger windows — now up to a million tokens or more — let you feed in long documents, entire codebases and full conversation histories in a single request, which is essential for research and long-document tasks.
Should I use one AI model or several?
Most effective teams use several, routing each task to the model that leads it — for example, Claude for code, Gemini for research, GPT-5.5 for customer-facing replies, and a cheap open model for high-volume work. Building a model-agnostic stack lets you swap models as the leaderboard changes without rebuilding.
How much do AI models cost to use?
API pricing ranges from about $0.10 to $75 per million tokens depending on the model and tier, with output tokens costing several times more than input. Frontier flagships like Claude Opus are the most expensive; value tiers and open models are dramatically cheaper. Estimate cost with your real usage before committing.
Do AI models make mistakes?
Yes. All models can hallucinate — produce confident but false information — and can reflect bias or be inconsistent. They generate plausible text rather than retrieve verified facts, so outputs should always be checked for accuracy, especially for high-stakes use. Grounding a model in your own data with retrieval reduces but does not eliminate errors.
12. Conclusion & Key Takeaways
The frontier of AI models is a fast-moving, crowded race, and that is good news: capability keeps rising while price-to-performance keeps improving. Right now Claude Opus 4.8 leads overall, with GPT-5.5, Gemini 3.1 Pro and Grok 4.3 close behind and a strong open ecosystem underneath — but the smarter takeaway than any single ranking is to match the model to the task and stay model-agnostic. Pick a default, route by use case, test cheaper tiers on real work, and keep a human checking the output. To go deeper, see our guides to generative AI, the best AI agents built on these models, and the best AI tools for business.
- Claude Opus 4.8 is the current overall leader; GPT-5.5, Gemini 3.1 Pro and Grok 4.3 complete the frontier.
- There is no universal best — Claude for coding/writing, Gemini for reasoning/value, GPT-5.5 for creative, open models for cost.
- Pricing ranges from ~$0.10 to $75 per million tokens; choose by price-to-performance and test on your own tasks.
- Open models (Llama 4, DeepSeek) are now genuinely competitive for high-volume, private or budget work.
- Stay model-agnostic and route by task — leaderboards change monthly, so build to swap models cheaply.
The “best AI model” is a moving target — but the winning strategy is steady: pick by task, route intelligently, test on real work, and keep a human in the loop. Build to swap, and every new flagship becomes an upgrade rather than a migration.
4 Comments
Pingback: OpenAI Just Made GPT-5.5 the Default ChatGPT Model — Here's What Changes for Everyone - TechNova AI
This piece of writing is in fact a nice one it helps new the web viewers,
who are wishing for blogging.
Hi there! I could have sworn I’ve been to this blog before but after
browsing through many of the articles I realized it’s new to me.
Anyhow, I’m certainly delighted I came across it
and I’ll be book-marking it and checking back often!
Thank you for taking the time to share your thoughts! We truly appreciate the support and are glad you found value here. Stay connected—there’s more helpful content coming your way.